正規表現基礎
+ 繰り返し
カテゴリー:量指定子

1回は必要!
前回は量指定子の中でも、0 回以上の繰り返しを表す * を紹介しました。
今回は、0回ではなく1回は必要になる + を説明します。
+ は、直前の正規表現を 1 回以上繰り返したものにマッチさせる正規表現です。
記述方法ですが、* の場合とよく似ています。
例えば e の1回以上の繰り返しは、e+ のように記述します。
そして、パターンを be+ とすると、be や bee にはマッチしますが、b にはマッチしません。
繰り返し対象の e が無いためです。
パターンが be+ の場合

* との違いに注意しながら、以下で簡単な例を実行しましょう。
この記事の難度は、基礎 Cクラスです。
(A: やさしい → E: 難しい)
事前知識として、pythonから正規表現を扱う方法が必要になります。
また、正規表現における文字クラスの知識や、グループを表す正規表現である ( ) を理解している事が望ましいです。
(不安な人でも、【Pythonから使う】【基礎1 文字クラス】 【( ) グループを指定】【( ) キャプチャを使う】、で詳しい解説があるので安心です。)
* との違いに注意しながら、平易な例を通して + に慣れていきましょう。
| 難度 : | |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。正規表現の文字クラスやグループ等。 |
| 学習効果: | + が直前の正規表現を 1 回以上、できるだけ多く繰り返す事を理解できる。 |
Contens | 目次
| Chapter1 | Pythonで実行 |
Chapter1 Pythonで実行
a+
先ず文字列パターンを、アルファベット1文字の a と + を組み合わせて a+ とします。
これは a の1回以上の繰り返しを表します。
* とは異なり a の存在が必要なので、対象文字列が map なら、a の箇所のみにマッチするはずです。
re_meta25_1.py
import re
pattern = re.compile("a+")
st = "map"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
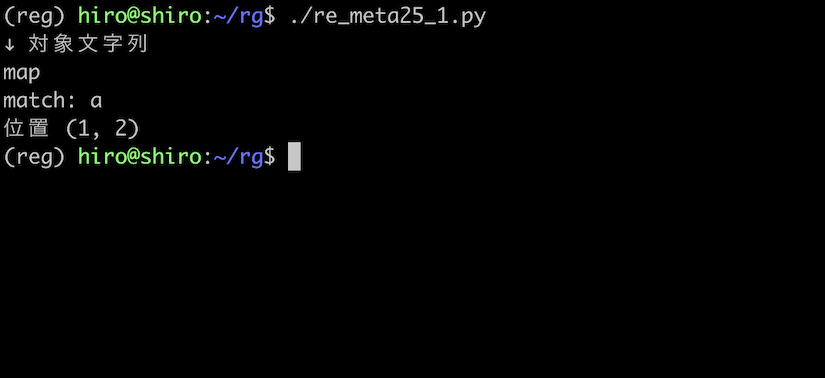
予想通り、a のみにマッチしました。
次にパターンを ma+p にします。
m と p の間の a が、1回以上繰り返されている場合にのみ一致するはずです。
re_meta25_2.py
import re
pattern = re.compile("ma+p")
st = "mp map maap"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
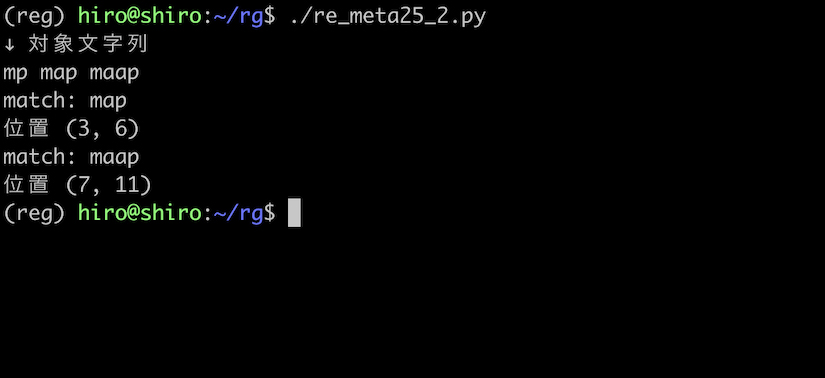
想定した結果になりました。
a が存在しない mp には一致せず、繰り返している map , maap には一致をみせました。
これに対して、対象文字列を mop としてしまうと、a の代わりに o が存在するのでマッチしません。
re_meta25_3.py
import re
pattern = re.compile("ma+p")
st = "mop"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
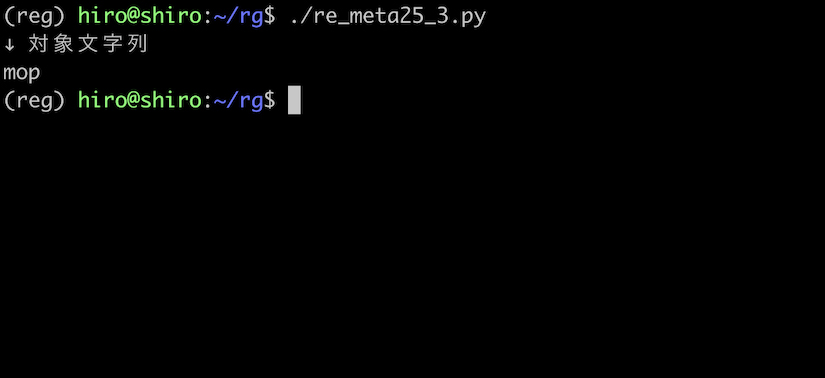
* のときと同様に、mop ではマッチしない事が確認出来ました。
さて、ここで冒頭で例示した bee について実行してみましょう。
パターンを be+ と構成する事で、e のできるだけ多くの繰り返しにマッチします。
よって、対象文字列が beeeeeee のように、e が多く繰り返されていてる場合でもヒットします。
re_meta25_4.py
import re
pattern = re.compile("be+")
st = "b be bee beeeeeee"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
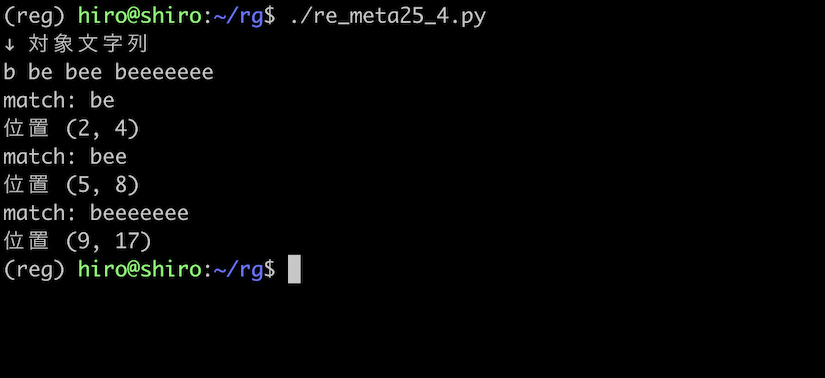
be だけでなく、bee や beeeeeee にもヒットしています。
(es)+
今度は、グループ化されたものを繰り返しの対象とします。
グループを表す正規表現は ( ) です。
(グループ については【( ) グループを指定】で詳しく説明しています。)
パターンを (es) の繰り返しにする場合、(es)+ のように記述します。
re_meta25_5.py
import re
pattern = re.compile("gen(es)+")
st = "gen genes geneses"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
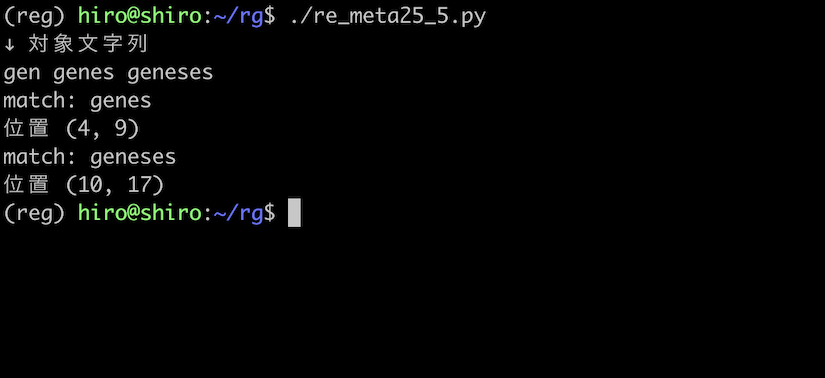
それぞれ、es の1回、2回の繰り返しである genes , geneses に一致しました。
また、 * の場合とは異なり、es の0回の繰り返しである gen には一致していません。
さらに、次の例では (es) の後方参照を試しています。
(後方参照 については【( ) キャプチャを使う】で詳しく説明しています。)
パターンは、シンプルに (es)+\1 にしましょう。
対象文字列は、先程と同様なものに geneseseses 加えた gen genes geneses geneseseses です。
re_meta25_6.py
import re
pattern = re.compile(r"gen(es)+\1")
st = "gen genes geneses geneseseses"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("----- match -----")
for i in range(result.lastindex + 1):
print('group{num};'.format(num = i),result.group(i))
print("位置",result.span(i))
実行結果
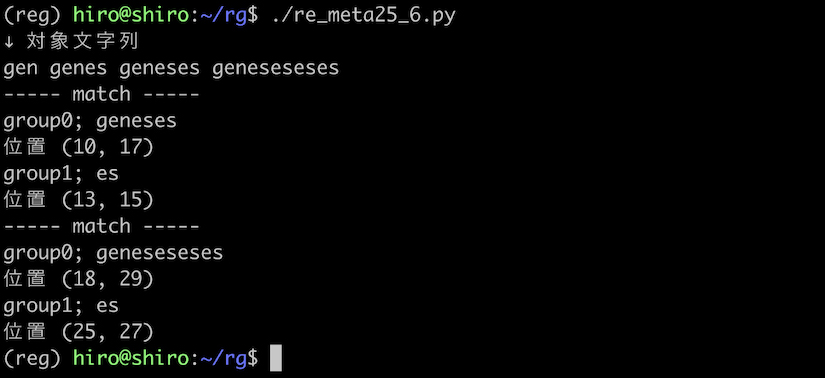
実行結果(続き)
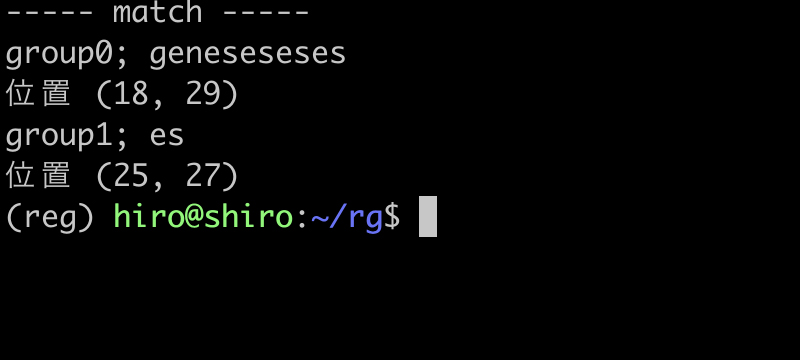
geneses , geneseseses にはマッチしました。
グループに量指定子を組み合わせてから、後方参照を (es)+\1 のように行っても、あくまで es と、その参照が必要になる事は変わらないようです。
なお、この結果は (es)*\1 のときと同様です。
((es)+)
次の例では、(es)+ 自体を ( ) で括ってグループ化してみましょう。
パターン以外は、一つ前に実行した meta25_6.py と同様にして、結果の違いに注意しながら試します。
re_meta25_7.py
import re
pattern = re.compile(r"gen((es)+)\1")
st = "gen genes geneses geneseseses"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("----- match -----")
for i in range(result.lastindex + 1):
print('group{num};'.format(num = i),result.group(i))
print("位置",result.span(i))
実行結果
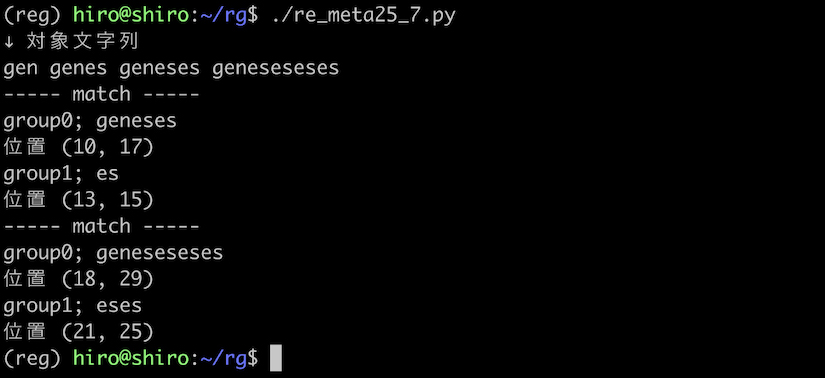
実行結果(続き)
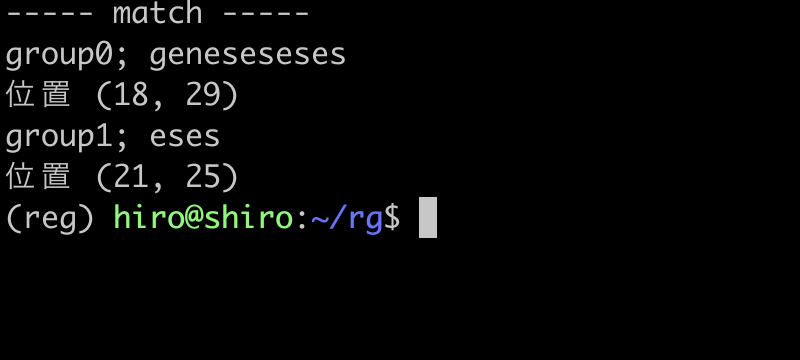
geneses , geneseseses につき、各々1回、2回分に該当する後方参照が行われたようです。
それ故に、meta25_6.py のときとは異なり、geneseseses は eses をキャプチャ対象としています。
\d+
続けて例を出します。
数字を表す文字クラスである \d と + を組み合わせて、数字の繰り返しを狙います。
(文字クラス については【\d 数字を指定する】で詳しく説明します。)
re_meta25_8.py
import re
pattern = re.compile("¥\d+")
st = "¥ ¥7 ¥77 ¥777"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
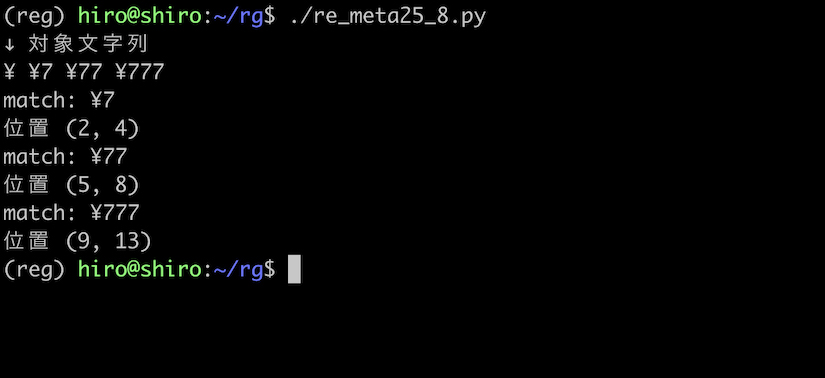
¥ 表示の金額を取得出来ました。
* のときとは違い、¥ のみでマッチする事は起こりません。
+ の説明はここで終了です。
多くの例をみてきたので、+ が直前の正規表現を 1 回以上、できるだけ多く繰り返す事を理解できました。
次回も引き続き量指定子の話です。
? について解説します。
関連記事

* 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | * が直前の正規表現を 0 回以上、できるだけ多く繰り返す事を理解できる。 |

+ 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | + が直前の正規表現を 1 回以上、できるだけ多く繰り返す事を理解できる。 |

? 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | ? が、直前の正規表現を0回か、1回繰り返したものにマッチさせる事を理解できる。 |

{ } 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | { } が、直前の正規表現を指定した回数、ちょうど繰り返したものにマッチさせる事を理解できる。 |

{ , } 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | {m,n} が、直前の正規表現を m 回から n 回、できるだけ多くの繰り返しにマッチする事が分かる。 |

*? +? ?? { , }? 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | *? +? ?? { , }? が、非貪欲 (non-greedy)のマッチになる事を理解できる。 |

正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |