正規表現基礎
( ) キャプチャを使う
カテゴリー:グループ・選択

パターンの再利用
グループを表す正規表現である ( ) の第二回です。
パターンがマッチした際、( ) 中も取得出来る事を、第一回では主にみてきました。
この他にも( ) の機能として、グループ化された部分を、以降のパターンで再利用することも可能です。
所謂 キャプチャ というもので、( )のパターンを捕捉して保存することにより、後から参照出来るようにするものです。
例として、sets というパターンがあったとします。
これに対して、(s)ets とすると (s) の部分がグループ化されます。
また、sets の中で s の文字は、最初だけでなく最後にもあります。
そこで、キャプチャを利用してグループ化されている (s) を参照します。
記述方法は、 \number となり、number には参照したいグループ番号を指定します。
(なお、グループ番号は左から右へ一つずつ振られます。)
それ故に、 r"(s)et\1" とする事で、対象となる文字列に sets があった場合にはマッチします。
反対に、(?:s) とすると s はキャプチャされません。
キャプチャは、コード上で実行してみないと分かりにくいので、早速始めていきましょう。
この記事の難度は、基礎 Cクラスです。
(A: やさしい → E: 難しい)
事前知識として、pythonから正規表現を扱う方法が必要になります。
また、正規表現における文字クラスの知識や、置換処理を理解している事が望ましいです。
(不安な人でも、【正規表現をPythonから使うには ?】【基礎1 文字クラス】【正規表現による置換と分割】で詳しい解説があるので安心です。)
| 難度 : | |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。正規表現の文字クラスや置換処理等。 |
| 学習効果: | 後方参照が出来るようになる。 |
Contens | 目次
| Chapter1 | Pythonで実行 |
Chapter1 Pythonで実行
\1
キャプチャを試してみる前に、raw文字列記法について確認しておきます。
pythonでは、\ の後に数字を付けるとエスケープシーケンスとして機能します。
(エスケープシーケンス については【\ エスケープ文字の働き】で詳しく説明しています。)
つまり、\ooo のようにすると、8 進数値 ooo を持つ文字の意味になります。
故に、正規表現中で用いる場合は r を付けます。
なお、以下で使用するPythonのバージョンは 3.7 です。
re_meta16_1.py
print("rなし:","\1")
print("rあり:",r"\1")
実行結果
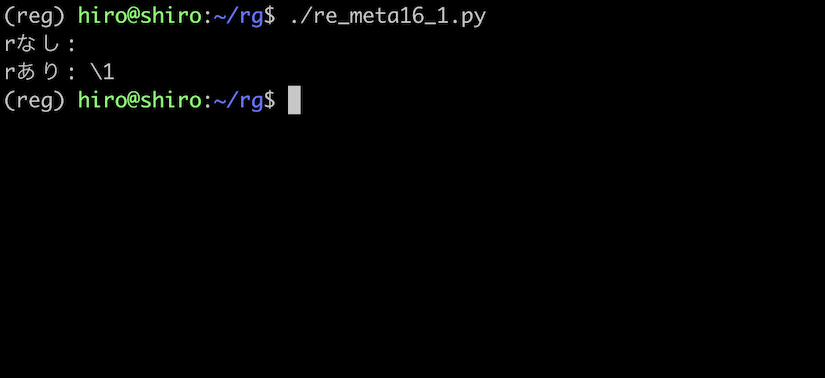
raw文字列記法により、エスケープシーケンスが無効になっている事が確認出来ました。
それではキャプチャを試してみましょう。
re_meta16_2.py
import re
pattern = re.compile(r"(s)et\1")
st ="sets"
result = pattern.search(st)
print(result)
実行結果
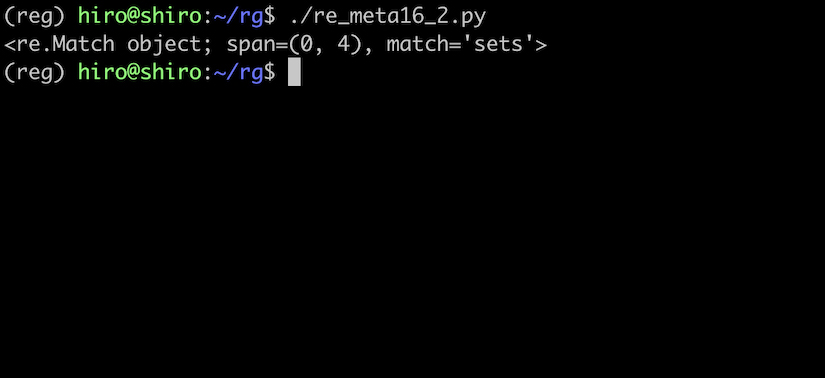
無事にマッチしました。
もう一つ例として、htmlのタグ(< >)で実行してみます。
re_meta16_3.py
import re
pattern = re.compile(r"<(h\d)>hello</\1>")
st ="<h1>hello</h1><h2>hello</h1><h3>hello</h3>"
result_iter = pattern.finditer(st)
for result in result_iter:
for i in range(result.lastindex + 1):
print('group{num};'.format(num = i),result.group(i))
print('group{num};'.format(num = i),result.span(i))
実行結果
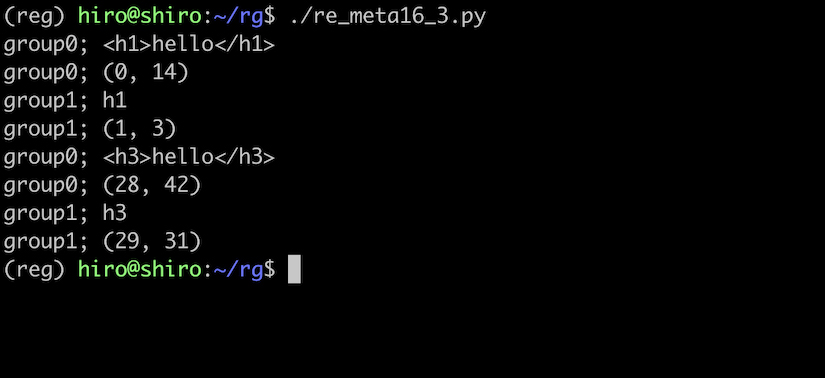
開始タグ名と、閉じタグ名が一致したものだけがマッチしています。
(( ))
今度はグループが入れ子になっている場合です。
この際の \number の指定方法は、一番左側の ( が \1 、二番目の ( が \2 、...となります。
re_meta16_4.py
import re
pattern = re.compile(r"(No(\d))_\1_\2")
st ="No7_No7_7 No1_1_No1"
result_iter = pattern.finditer(st)
for result in result_iter:
for i in range(result.lastindex + 1):
print('group{num};'.format(num = i),result.group(i))
print('group{num};'.format(num = i),result.span(i))
実行結果
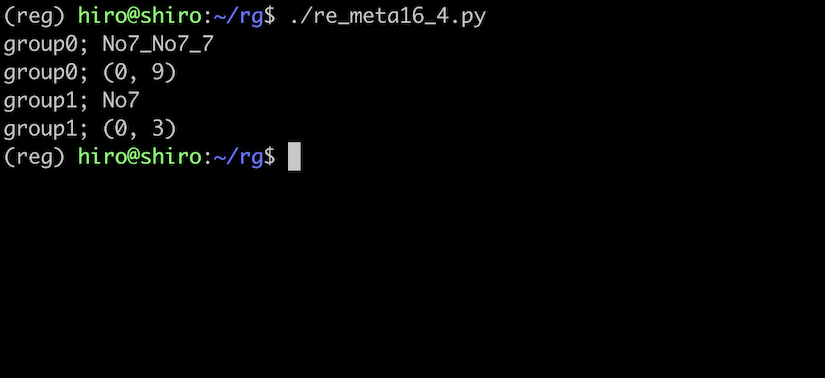
\1 が No7 を、\2 が 7 を参照している事が分かりました。
(?: )
キャプチャしない際は、(?: ) と表記します。
re_meta16_5.py
import re
# | (選択)を用いる。 tele か cell のどちらか。
pattern = re.compile("(?:tele|cell)(phone)")
st ="telephone cellphone headphone"
result_iter = pattern.finditer(st)
for result in result_iter:
for i in range(result.lastindex + 1):
print('group{num};'.format(num = i),result.group(i))
print('group{num};'.format(num = i),result.span(i))
実行結果
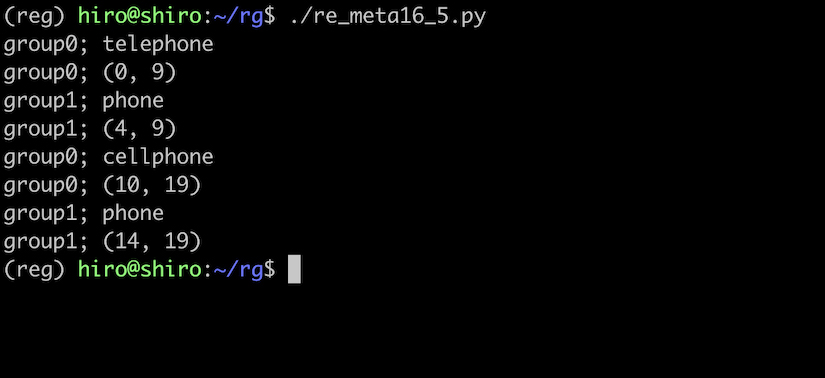
(phone) は、キャプチャされています。
一方、(?:tele | cell) は、されていません。
置換
グループ化された箇所は、置換の際にも参照する事が出来ます。
(置換 については【正規表現による置換と分割】で詳しく説明しています。)
置換後の文字列を指定する際に、\number(あるいは \g<number>) として、number の箇所にグループ番号を指定します。
re_meta16_6.py
import re
pattern = re.compile("(東京)都(品川)区")
st ="東京都品川区"
repl = r"\g<2>駅---\g<1>駅"
result = pattern.sub(repl,st)
print(result)
実行結果
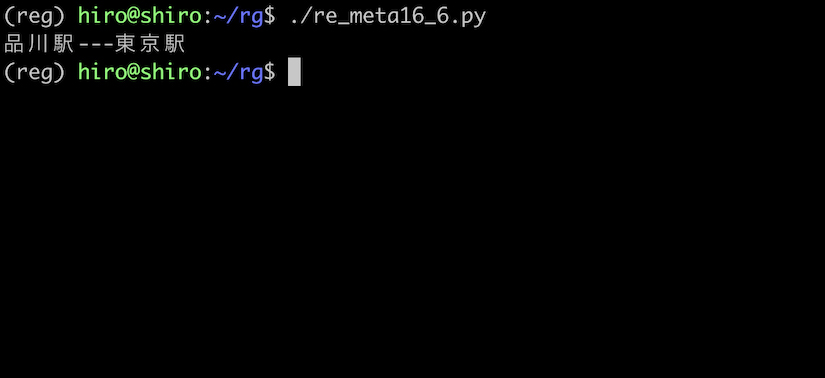
置換されている事を確認出来ました。
さて、グループ化の第二回は終了です。
後方参照が理解できました。
第三回は、グループ名を用いた処理です。
関連記事

| OR(または)
| 正規表現: | グループ・選択 |
| 難度 : | 入門〜基礎 |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。 |
| 学習効果: | 選択(OR) を習得し、[ ](文字クラス) との違いも理解出来る。 |

( ) グループを指定
| 正規表現: | グループ・選択 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法(reモジュールを含む) |
| 学習効果: | パターン中の一部分を取得する事が出来るようになる。 |
( ) キャプチャを使う
| 正規表現: | グループ・選択 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。正規表現の文字クラスや置換処理等。 |
| 学習効果: | 後方参照が出来るようになる。 |
( ) 名前つきグループ
| 正規表現: | グループ・選択 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎(reモジュールを含む)、置換処理等 |
| 学習効果: | 名前つきグループの全般の処理。特に、後方参照を任意の名前で出来るようになる。 |

正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |