正規表現基礎
\d 数字を指定する
カテゴリー:文字クラス

ジャワ語にマッチ ?
正規表現では、定義済みの文字クラスというものがあります。
これは前述の文字クラスの中でも、比較的よく用いられるパターンを別名で定義したものです。
例えば、数字は文字クラスとして [0-9] と表現できます。
この [0-9] に対して、別名で同様の意味を持たせたのが定義済みの文字クラスです。
[0-9] なら \d と定義されます。
定義済み文字クラスのイメージ

ここで注意が必要な場合があります。
プログラミング言語によっては、 \d が 0 ~ 9 以外の文字も含んでいる事です。
これを回避する為にフラグを用いる必要があります。
この事も含めて、以下で \d を実行してみましょう。
この記事の難度は、基礎 Cクラスです。
(A: やさしい → E: 難しい)
事前知識として、pythonから正規表現を扱う方法が必要になります。
| 難度 : | |
| 事前知識: | Pythonの基礎文法(reモジュールを含む) |
| 学習効果: | \d を用いて、数字を 狭義/広義 にマッチさせる事が出来るようになる。 |
Contens | 目次
| Chapter1 | Pythonで実行 |
Chapter1 Pythonで実行
ジャワ数字にもマッチ可能
\d をPythonで実行してみましょう。
使用するPythonのバージョンは 3.7 です。
先ずは 0 ~ 9 の数字にマッチするか確認します。
re_meta3_1.py
import re
pattern = re.compile("\d")
st ="0123456789"
result = pattern.findall(st)
print(result)
実行結果
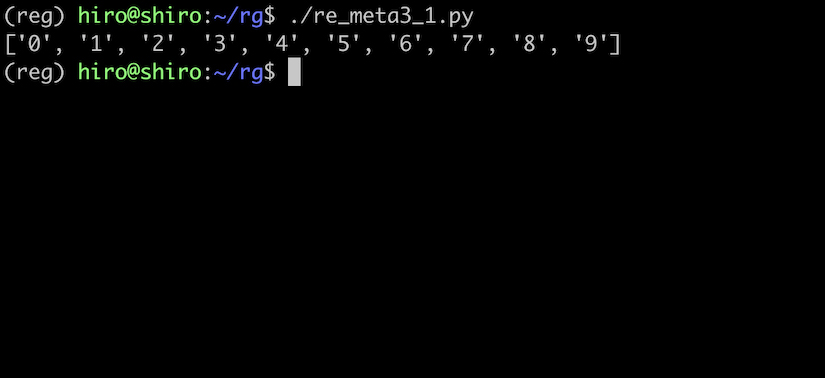
しっかりマッチしています。
さて、pythonの公式ドキュメントによると \d につき
"Unicode (str) パターンでは:
任意の Unicode 10 進数字 (Unicode 文字カテゴリ [Nd]) にマッチします。これは [0-9] とその他多数の数字を含みます" (Pythonの公式ドキュメントより引用)
とあります。
この Nd というのは Unicode Characters in the 'Number, Decimal Digit' Category であると思われます。
ここには 0 ~ 9 以外の他、全角の0 ~ 9 や ꧓(3の意味)のようなジャワ文字も含まれているようです。
本当にジャワ文字まで一致するのか試してみましょう。
re_meta3_2.py
import re
pattern = re.compile("\d")
st ="09 034 七 なな イチ ꧓"
result = pattern.findall(st)
print(result)
実行結果
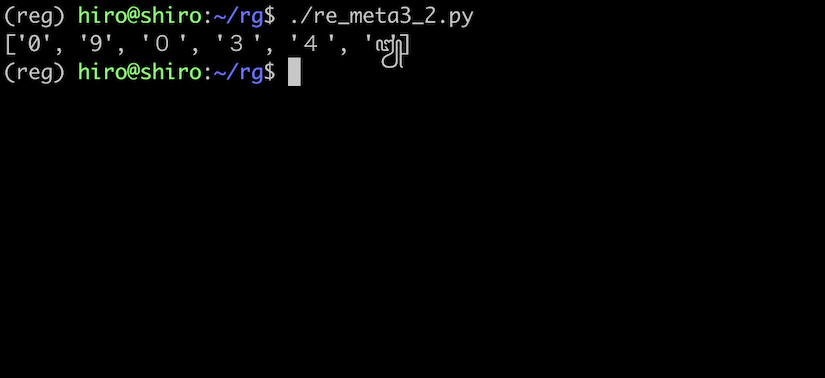
なんと全角数字の他に ꧓ までマッチしました。
このような状態は、数字を全角までも含めて幅広くマッチさせたい場合には有用でしょう。
しかし、0 ~ 9 のみ一致対象としたい場合には、どうすればよいのでしょうか?
一つの解決策として、pythonの公式ドキュメントには以下のような記述があります。
"8 ビット (bytes) パターンでは:
任意の 10 進数字にマッチします。これは [0-9] と等価です。" (Pythonの公式ドキュメントより引用)
どうやらエンコードすればよさそうです。
先程のコードをエンコードして再実行してみます。
re_meta3_3.py
import re
pt = "\d".encode('utf-8')
print(type(pt),pt)
pattern = re.compile(pt)
st ="09 02꧓"
st = st.encode('utf-8')
print(type(st),"\n",st)
result = pattern.findall(st)
print(result)
実行結果
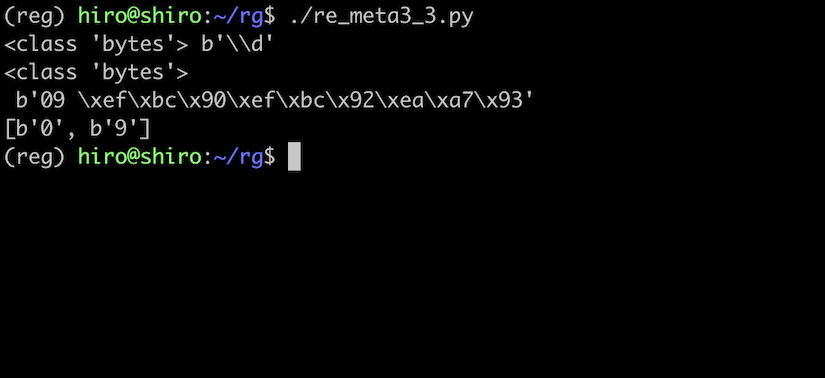
見事に余計な文字を弾けました。
ASCII フラグ
しかしながら、エンコード処理は少々面倒です。
そこで、 ASCII フラグ を利用します。
エンコードした場合と同様の効果が得られます。
re_meta3_4.py
import re
pattern = re.compile("\d",flags=re.ASCII)
st ="09 034 七 なな イチ ꧓"
result = pattern.findall(st)
print(result)
実行結果
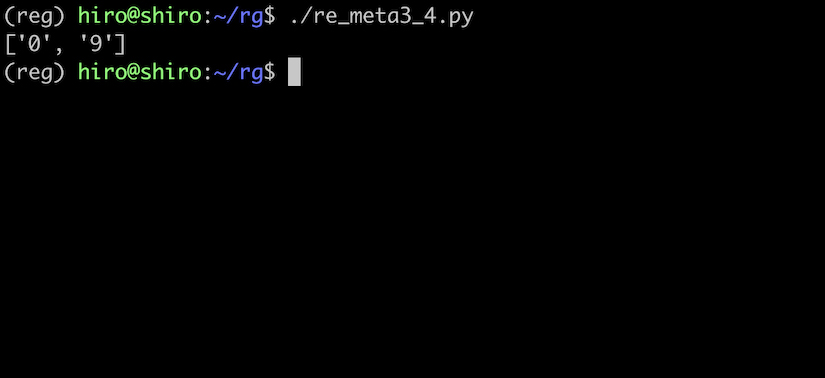
全角の数字などを除く事ができました。
これで、文字クラス [0-9] と等しくなりました。
インラインフラグ
この他に、インラインフラグを用いる方法もあります
これは文字列パターンの先頭に (?a) を記述する事で、re_meta3_4.py と結果が等しくなります。
re_meta3_5.py
import re
pattern = re.compile("(?a)\d")
st ="09 034 七 なな イチ ꧓"
result = pattern.findall(st)
print(result)
実行結果
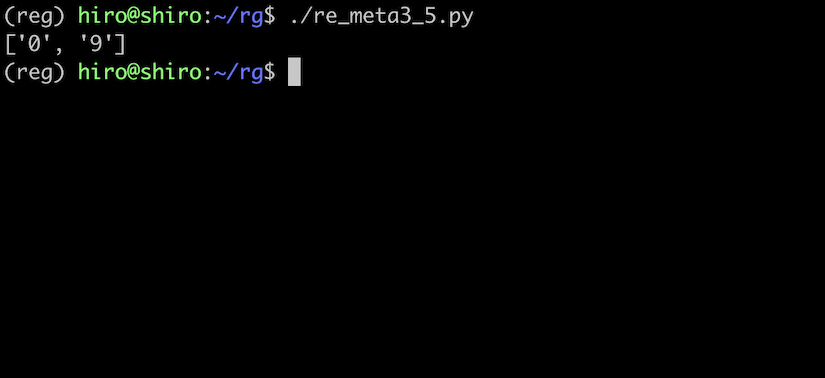
上と同様に、全角数字などはマッチしていません。
以上で \d については終了です。
[0-9] 以外で、数字を表現する方法を習得しました。
また、数字に対するマッチの際に、フラグを用いて広義か狭義かを選択する事もできるようになりました。
次回は d を大文字にした \D について言及します。
関連記事

[ ] 文字集合を指定する
| 正規表現: | 文字クラス |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法(reモジュールを含む) |
| 学習効果: | 文字クラスを細部まで理解できる。 |

\d 数字を指定する
| 正規表現: | 文字クラス |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法(reモジュールを含む) |
| 学習効果: | \d を用いて、数字を 狭義/広義 にマッチさせる事が出来るようになる。 |

\D 数字以外を指定する
| 正規表現: | 文字クラス |
| 難度 : | 入門〜基礎 |
| 事前知識: | Pythonの基礎文法。正規表現の文字クラス等。 |
| 学習効果: | \D を用いて、数字以外を 狭義/広義 にマッチさせる事が出来るようになる。 |

\w 単語構成文字
| 正規表現: | 文字クラス |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法。正規表現の文字クラス等。 |
| 学習効果: | \w を用いて、単語構成文字を 狭義/広義 にマッチさせる事が出来るようになる。 |

\W 単語構成文字以外
| 正規表現: | 文字クラス |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法。正規表現の文字クラス等。 |
| 学習効果: | \W を用いて、単語構成文字以外を 狭義/広義 にマッチさせる事が出来るようになる。 |

\s 空白文字を指定する
| 正規表現: | 文字クラス |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法。正規表現の文字クラス等。 |
| 学習効果: | \s を用いて、空白文字を 狭義/広義 にマッチさせ、余白を適切に消す事が出来るようになる。 |

\S 空白以外を指定する
| 正規表現: | 文字クラス |
| 難度 : | 入門〜基礎 |
| 事前知識: | Pythonの基礎文法。正規表現の文字クラス等。 |
| 学習効果: | \S を用いて、空白文字以外を 狭義/広義 にマッチさせ、余白以外の文字を取得できる。 |

. 改行以外の任意の1文字
| 正規表現: | 文字クラス |
| 難度 : | 入門〜基礎 |
| 事前知識: | Pythonの基礎文法。エスケープ文字である \ (バックスラッシュ)等。 |
| 学習効果: | . を用いて、幅広いマッチが出来るようになる。 |

正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |