正規表現基礎
{ , } 繰り返し
カテゴリー:量指定子

範囲を持たせて...
前回から引き続き、量指定子の { } についての説明です。
{ } が、直前の正規表現を指定した回数、ちょうど繰り返したものにマッチさせる事を前回学習しました。
今回は、繰り返し回数に範囲を持たせる事をみていきます。
具体的には、{ } の中に , を付けて { , } のようにすると、繰り返し回数に範囲を持たせる事が可能です。
記述例として e{1,3} で、1個から3個の e にマッチします。
つまり {m,n} は、直前の正規表現を m 回から n 回、できるだけ多く繰り返したものにマッチさせる正規表現という訳です。
それゆえに、文字列パターンを be{1,3} とすると、be や bee にはマッチしますが、beeeeeee などにはマッチせずに beee までのマッチになります。
パターンが be{1,3} の場合

また、{m,n} において m を省略して {,n} にすると下限は 0 に指定されます。
例えば、e{,3} なら e の0回から3回までの繰り返しを表します。
先程のパターンに適用して be{,3} にするならば、b や be あるいは bee にマッチし、beeeeeee には beee までマッチします。
パターンが be{,3} の場合

さらに {m,n} につき、{m,} のように n を省略すると上限は無限に指定されます。
よって、e{1,} で e の1回以上で上限無しの繰り返しを表現しています。
パターンが be{1,} なら、be や bee ないしは beeeeeee と一致します。
パターンが be{1,} の場合

ところで、前回までに説明した量指定子である * + ? は、{ , } を用いて表現できる事に気付いたでしょうか?
つまり、{0,} は * と等しく、 {1,} は + と、そして {0,1} は ? と同様の表現です。
* + ? を { , } を用いて表現する

それでは、シンプルな例を使って { , } の動作を確認していきましょう。
この記事の難度は、基礎 Cクラスです。
(A: やさしい → E: 難しい)
事前知識として、pythonから正規表現を扱う方法が必要になります。
また、正規表現における文字クラスの知識や、グループを表す正規表現である ( ) を理解している事が望ましいです。
(不安な人でも、【Pythonから使う】【基礎1 文字クラス】 【( ) グループを指定】【( ) キャプチャを使う】、で詳しい解説があるので安心です。)
記述方法に注意しながら、繰り返しに範囲を持たせる事を試していきましょう。
| 難度 : | |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。正規表現の文字クラスやグループ等。 |
| 学習効果: | {m,n} が、直前の正規表現を m 回から n 回、できるだけ多く繰り返したものにマッチさせる事を理解できる。 |
Contens | 目次
| Chapter1 | Pythonで実行 |
Chapter1 Pythonで実行
a{1,2}
先ず文字列パターンを、アルファベット1文字の a と {1,2} を組み合わせて a{1,2} とします。
これは a の1回から2回までの繰り返しを表します。
a は1個か2個必要なので、対象文字列が map なら a にマッチするはずです。
re_meta28_1.py
import re
pattern = re.compile("a{1,2}")
st = "map"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
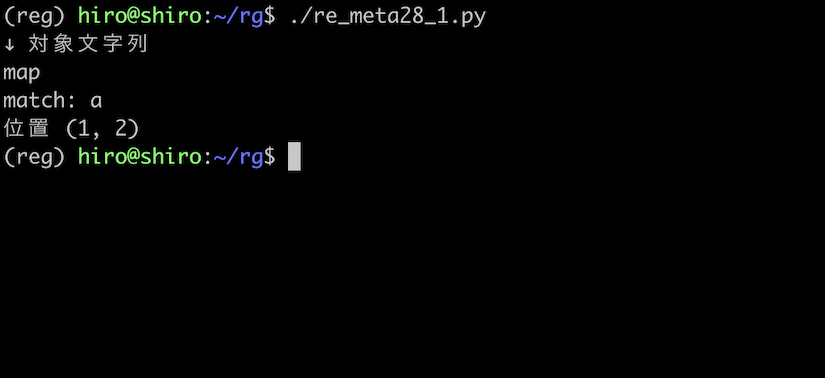
予想通り、a にマッチしました。
次にパターンを ma{1,2}p にします。
m と p の間に a が1個か2個ある場合にのみ一致するはずです。
re_meta28_2.py
import re
pattern = re.compile("ma{1,2}p")
st = "mp map maap"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
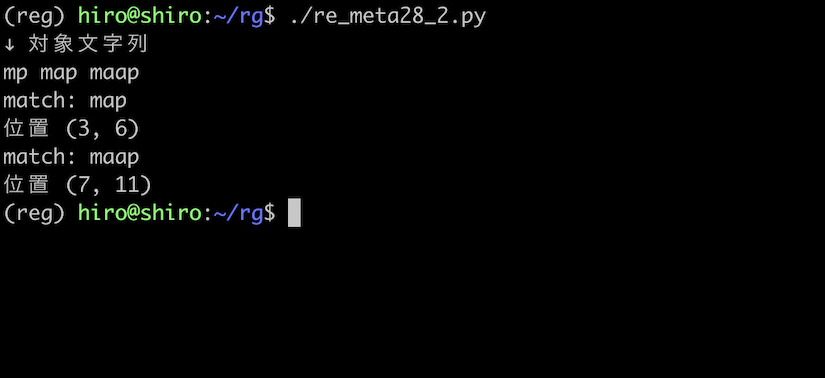
a が1個の map 及び、2回繰り返している maap に一致しました。
これに対して、対象文字列を mop としてしまうと、a の代わりに o が存在するのでマッチしません。
re_meta28_3.py
import re
pattern = re.compile("ma{1,2}p")
st = "mop"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
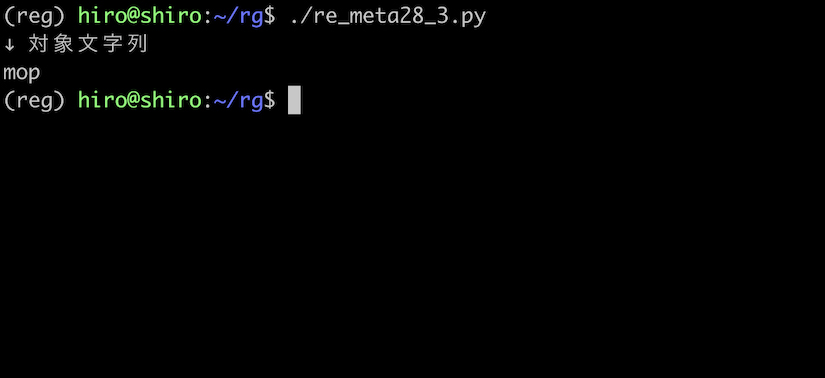
mop ではマッチしない事が確認出来ました。
e{1,3} e{,3} e{1,}
さて、ここで冒頭で例示した bee について実行してみましょう。
先ずパターンを be{1,3} と構成する事で、e の1回から3回の繰り返しにマッチさせます。
対象文字列が beeeeeee のように、e が多く繰り返されていてる場合でも、3回分の繰り返しまでしかヒットしないはずです。
re_meta28_4.py
import re
pattern = re.compile("be{1,3}")
st = "b be bee beeeeeee"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
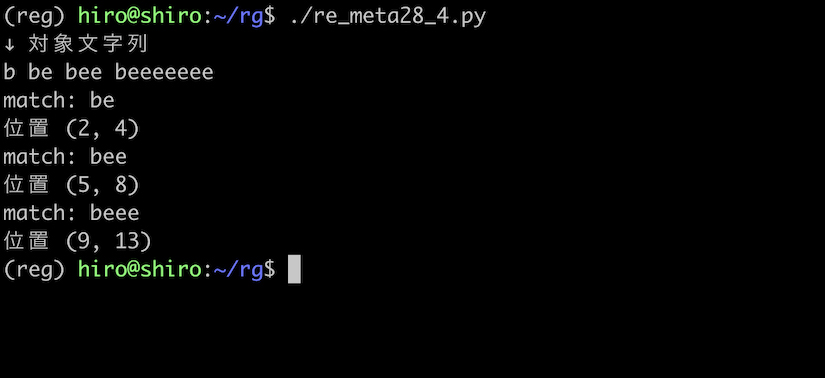
想定通り、e の1回、2回分の繰り返しである be や bee にマッチし、beeeeeee は、beee までしかヒットしていません。
次にパターンを be{,3} と構成する事で、e の3回以内の繰り返しにマッチさせます。
re_meta28_5.py
import re
pattern = re.compile("be{,3}")
st = "b be bee beeeeeee"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
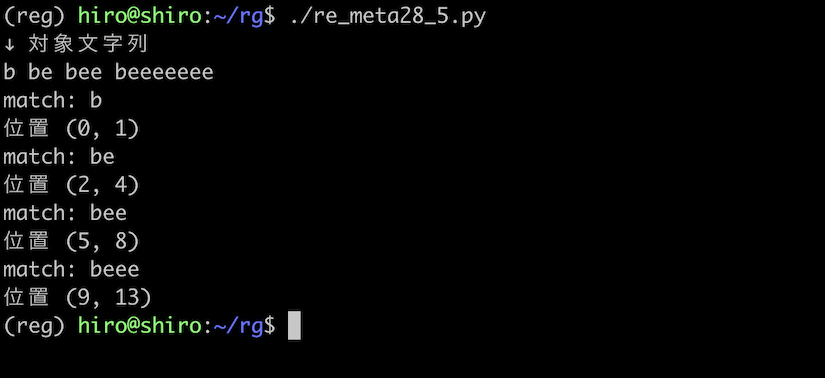
実行結果(続き)
be{1,3} のときとは異なり、e の0回の繰り返しである b にも一致しています。
その他は、be{1,3} と同様です。
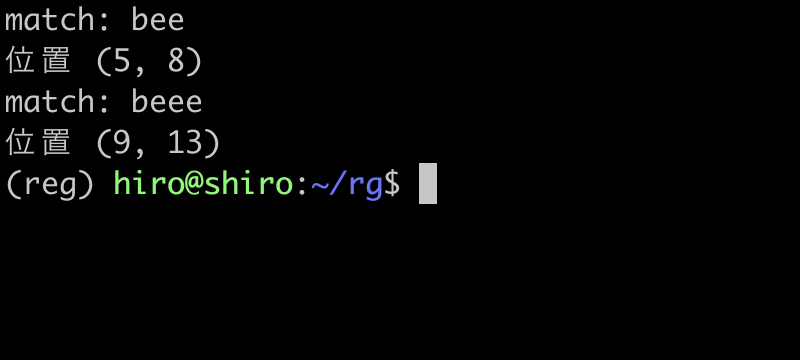
今度は、文字列パターンを be{1,} として、e の1回以上の繰り返しにマッチさせます。
re_meta28_6.py
import re
pattern = re.compile("be{1,}")
st = "b be bee beeeeeee"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
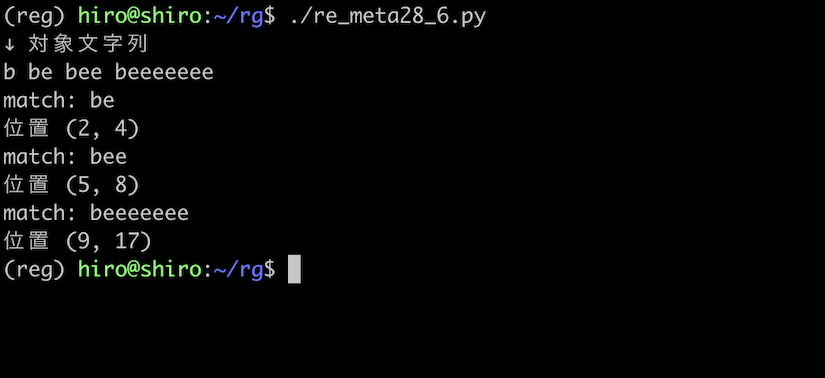
e の繰り返しの上限が無くなったので beeeeeee にもマッチしました。
(es){1,2}
今度は、グループ化されたものを繰り返しの対象とします。
グループを表す正規表現は ( ) です。
(グループ については【( ) グループを指定】で詳しく説明しています。)
パターンを (es) の繰り返しにする場合、(es){1,2} のように記述します。
re_meta28_7.py
import re
pattern = re.compile("gen(es){1,2}")
st = "gen genes geneses"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
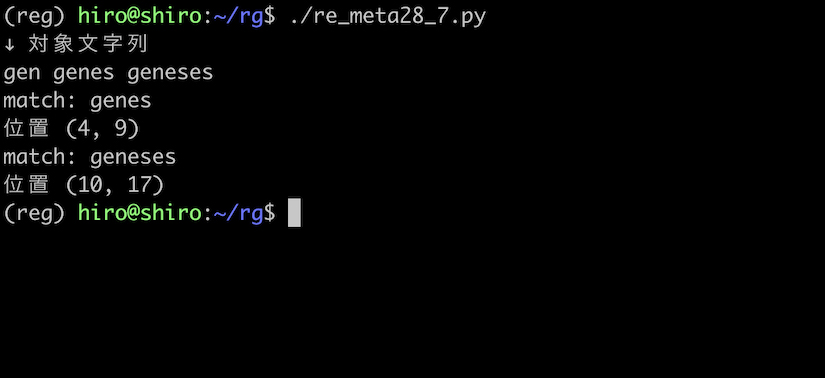
それぞれ、es が1つの場合は genes 、2つのときは、geneses に一致しています。
さらに、次の例では (es) の後方参照を試しています。
(後方参照 については【( ) キャプチャを使う】で詳しく説明しています。)
パターンは、シンプルに (es){1,2}\1 にしましょう。
対象文字列は、先程と同様なものに geneseseses 加えた gen genes geneses geneseseses です。
re_meta28_8.py
import re
pattern = re.compile(r"gen(es){1,2}\1")
st = "gen genes geneses geneseseses"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("----- match -----")
for i in range(result.lastindex + 1):
print('group{num};'.format(num = i),result.group(i))
print("位置",result.span(i))
実行結果
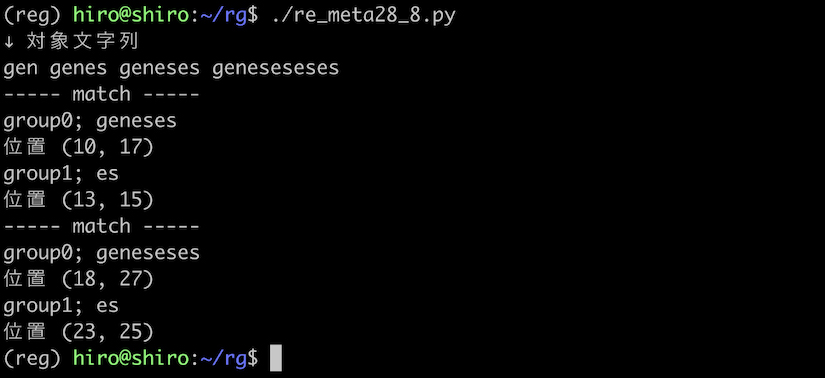
実行結果(続き)
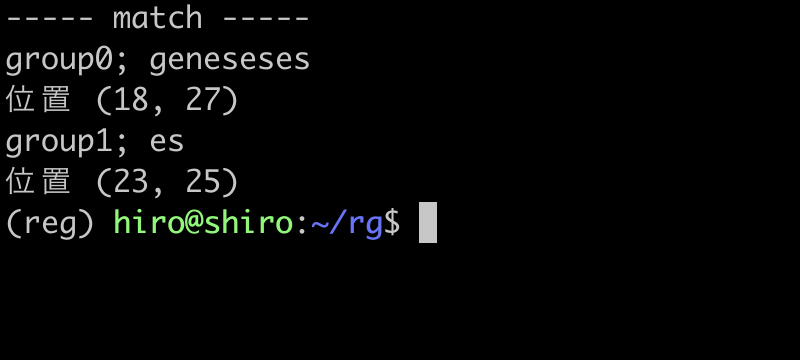
geneses , geneseseses の geneseses の箇所 にはマッチしました。
グループに量指定子を組み合わせてから、後方参照を (es){1,2}\1 のように行っても、あくまで es と、その参照が必要になる事は変わらないようです。
もう一つ例として、(es){1,}\1 の場合も試してみましょう。
re_meta28_9.py
import re
pattern = re.compile(r"gen(es){1,}\1")
st = "gen genes geneses geneseseses"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("----- match -----")
for i in range(result.lastindex + 1):
print('group{num};'.format(num = i),result.group(i))
print("位置",result.span(i))
実行結果
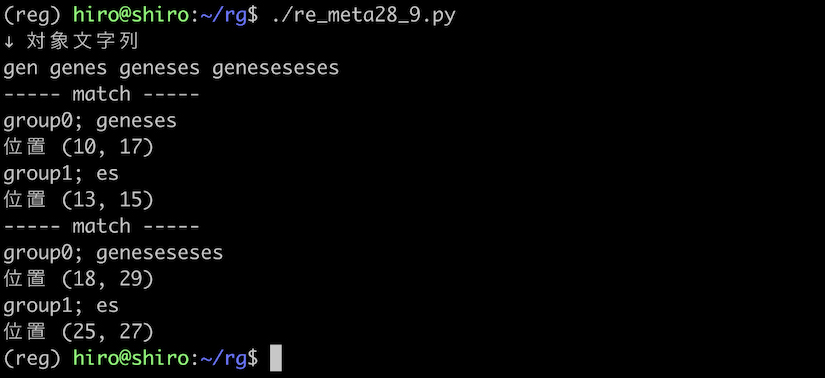
実行結果(続き)
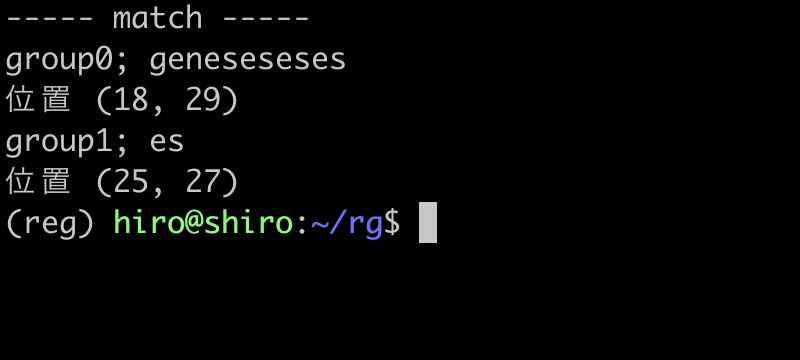
この場合は、geneseseses にもマッチしました。
((es){1,2})
次の例では、(es){1,2} 自体を ( ) で括ってグループ化してみましょう。
パターン以外は、前に実行した meta28_8.py と同様にして、結果の違いに注意しながら試します。
re_meta28_10.py
import re
pattern = re.compile(r"gen((es){1,2})\1")
st = "gen genes geneses geneseseses"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("----- match -----")
for i in range(result.lastindex + 1):
print('group{num};'.format(num = i),result.group(i))
print("位置",result.span(i))
実行結果
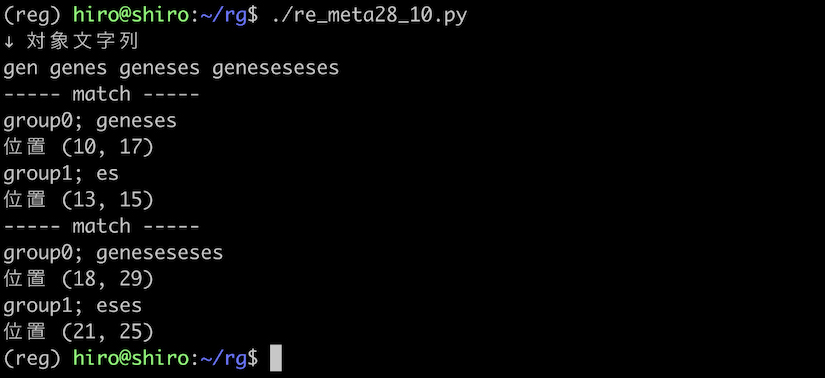
実行結果(続き)
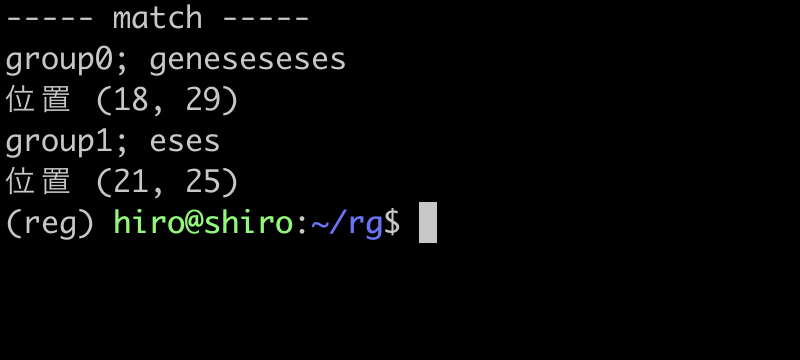
geneses , geneseseses につき、各々1回分と2回分の繰り返しに該当する後方参照が行われたようです。
\d{1,2}
続けて例を出します。
数字を表す文字クラスである \d と { , } を組み合わせて、数字の繰り返しを狙います。
(文字クラス については【\d 数字を指定する】で詳しく説明します。)
re_meta28_11.py
import re
pattern = re.compile("¥\d{1,2}")
st = "¥ ¥7 ¥57 ¥287"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
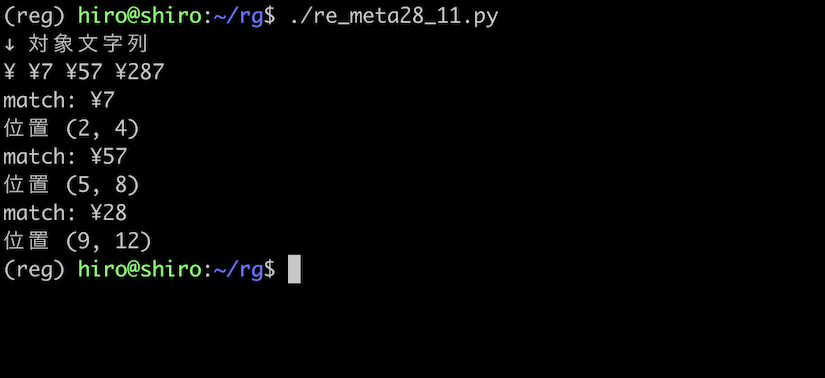
¥ 表示の金額を左から1桁あるいは、2桁分取得出来ました。
{0,} = *
最後に、{0,} は * と等しく、 {1,} は + と、そして {0,1} は ? と同様になる事を確認しましょう。
最初は {0,} = * です。
be{0,} を実行します。
re_meta28_12.py
import re
pattern = re.compile("be{0,}")
st = "b be bee beeeeeee"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
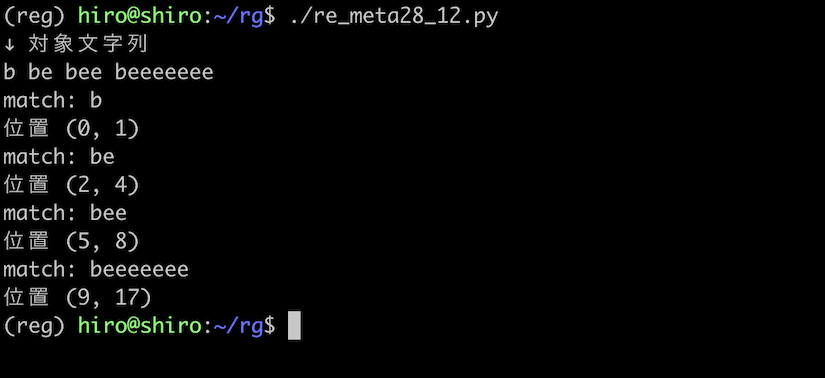
実行結果(続き)
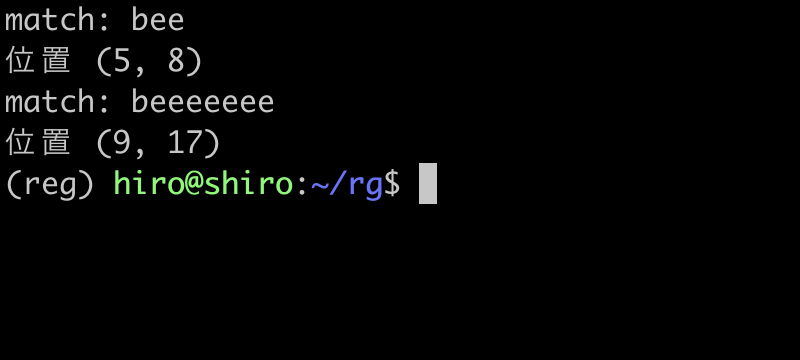
be* の実行
re_meta28_13.py
import re
pattern = re.compile("be*")
st = "b be bee beeeeeee"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
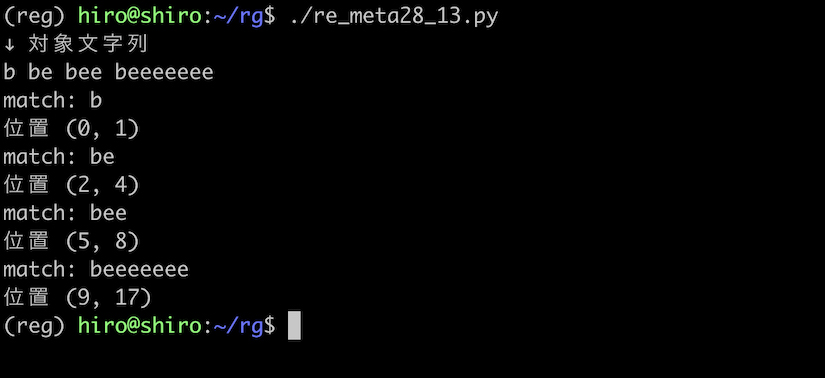
実行結果(続き)
{0,} は * は等しい結果になりました。
{1,} = +
続いて {1,} = + の確認です。
be{1,} の実行です。
re_meta28_14.py
import re
pattern = re.compile("be{1,}")
st = "b be bee beeeeeee"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
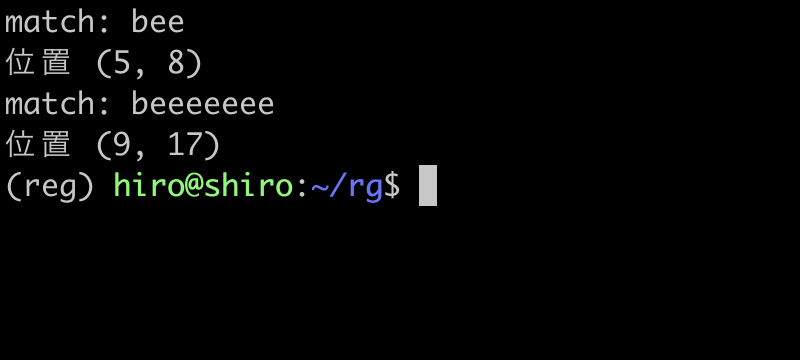
実行結果
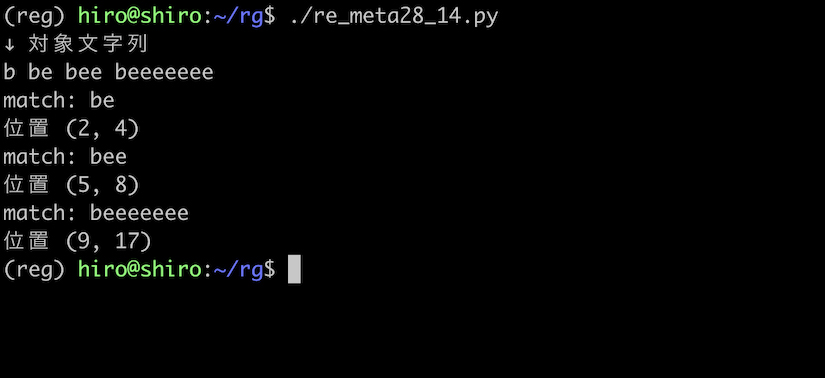
be+ の実行
re_meta28_15.py
import re
pattern = re.compile("be+")
st = "b be bee beeeeeee"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
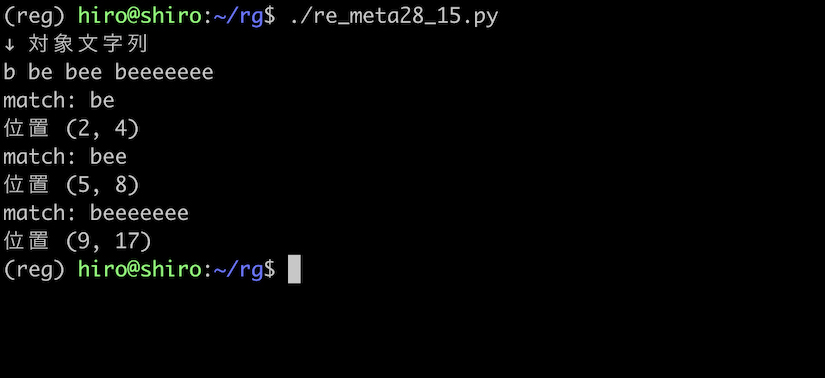
{1,} と + が同様である事を確認出来ました。
{0,1} = ?
次は {0,1} = ? である事を確かめます。
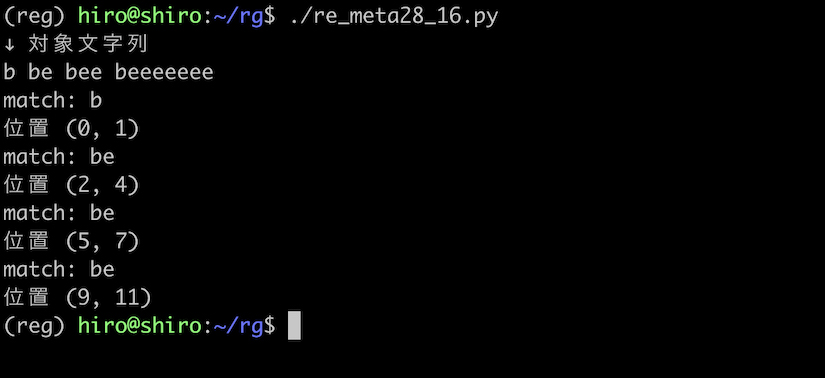
be{0,1} の実行
re_meta28_16.py
import re
pattern = re.compile("be{0,1}")
st = "b be bee beeeeeee"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
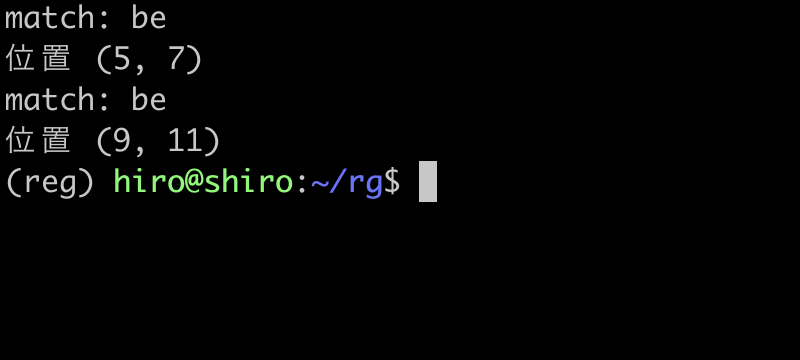
実行結果
実行結果(続き)
be? の実行
re_meta28_17.py
import re
pattern = re.compile("be?")
st = "b be bee beeeeeee"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
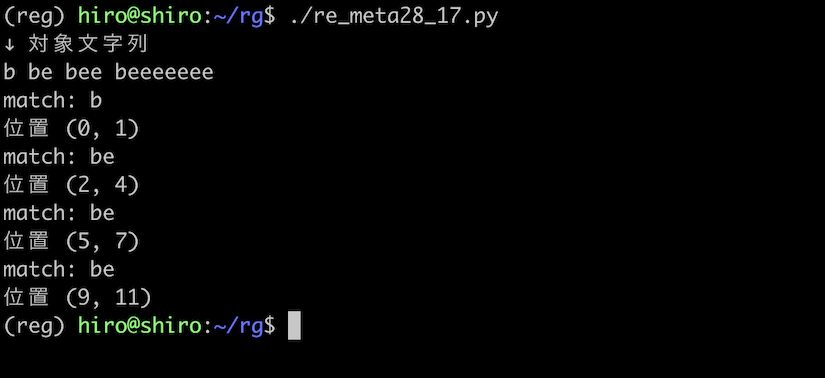
実行結果(続き)
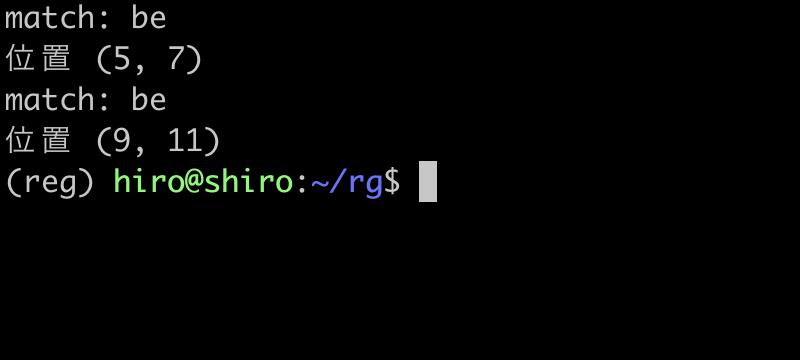
{0,1} と ? も実行結果が等しくなる事を確かめられました。
以上で { , } の説明は終了にします。
{m,n} は、直前の正規表現を m 回から n 回、できるだけ多く繰り返したものにマッチさせる事を理解できました。
また、* + ? を { , } を用いて表現できる事も分かりました。
ここまでの学習で量指定子の多くを習得出来ました。
残るはあと少しです。
* や + の後に ? を追加すると、非貪欲 (non-greedy) あるいは 最小 (minimal) のマッチが行われる事を次回に解説します。
関連記事

* 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | * が直前の正規表現を 0 回以上、できるだけ多く繰り返す事を理解できる。 |

+ 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | + が直前の正規表現を 1 回以上、できるだけ多く繰り返す事を理解できる。 |

? 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | ? が、直前の正規表現を0回か、1回繰り返したものにマッチさせる事を理解できる。 |

{ } 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | { } が、直前の正規表現を指定した回数、ちょうど繰り返したものにマッチさせる事を理解できる。 |

{ , } 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | {m,n} が、直前の正規表現を m 回から n 回、できるだけ多くの繰り返しにマッチする事が分かる。 |

*? +? ?? { , }? 繰り返し
| 正規表現: | 量指定子 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスやグループ等。 |
| 学習効果: | *? +? ?? { , }? が、非貪欲 (non-greedy)のマッチになる事を理解できる。 |

正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |