正規表現実践
電話番号
カテゴリー:定形の数字形式

電話番号をGET!
前回【クレジットカード番号】に引き続き、今回も特定の形式で並んでいる数字をマッチの対象にします。
第二回は電話番号です。
クレジットカード番号と同様に、電話番号も定形の数字形式で構成されています。
まずは、電話の中でも携帯電話の番号からみていきましょう。
携帯電話
携帯電話の番号は 11桁 です。
11桁の中でも最初の 3桁 は、090 か 080 あるいは 070 である事が必要です。
また、番号の途中で -(ハイフン) があり、3桁-4桁-4桁 のように区切られる場合もある。
というパターンを正規表現に落とし込みます。
まずは11桁の部分から考えましょう。
これは、【[ ] 文字集合を指定する】 と 【{ } 繰り返し】 で学習した文字クラスと量指定子を用いて、[0-9]{11} と表現すればよさそうです。
但し、最初の 3桁分 は 090 か 080 あるいは 070 であることが必要になるので、0[7-9]0 にします。
続けて書くと、0[7-9]0[0-9]{8} の形になります。
?
次は、-(ハイフン) があるときのパターンです。
-(ハイフン) で、3桁-4桁-4桁に区切られます。
最初の3桁分は既に区切られているので、残りの8桁分を 4桁ずつに分けて [0-9]{4}[0-9]{4} とします。
そして、各々の桁の間に -(ハイフン) を挟めばよいので 0[7-9]0-[0-9]{4}-[0-9]{4} の形にします。
残るは -(ハイフン) につき省略形で表現することですが、これはメタキャラクタの ? を用いれば解決出来そうです。
省略形を表せる ? によって -? と記述します。
全体では 0[7-9]0-?[0-9]{4}-?[0-9]{4} になります。
(? については、【? 繰り返し】で学習済みです。)
なお、前回のクレジットカード編と同様に、対象文字列の状態によりパターンを変化させます。
これについては下の実行例で説明しますが、その前に固定電話についても触れておきます。
固定電話
固定電話についての主なパターンは、以下のようになっています。
[0 市外局番] [市内局番] [加入者番号]の 10桁 形式。
最初の 1桁(国内プレフィックス)は 0 。
市外局番は 1~4桁 で、市内局番も 1~4桁 であり、両方合わせて 5桁 です。
加入者番号については、4桁 になります。
また、携帯電話と同様 -(ハイフン) がある場合も考慮し、その場合は [0 市外局番]-[市内局番]-[加入者番号] の形式にします。
以上の事を正規表現で構成します。
基本的には文字クラスと量指定子を、携帯電話のときと同様に用います。
けれども、市外局番と市内局番を合わせて 5桁 なので、各々場合分けを考えます。
一つ目のケースとして、市外局番が 1桁 で市内局番が 4桁 なら [0-9][0-9]{4} です。
次の場合は、市外局番が 2桁 で市内局番が 3桁 のときで、[0-9]{2}[0-9]{3} になります。
三つ目、四つ目では、市外局番が 3桁 で市内局番が 2桁、市外局番が 4桁 で市内局番が 1桁 という具合です。
|
この4つのケースを選択的に構成するための正規表現は | を用いて、以下のようにするのが一番分かりやすいと思います。
[0-9][0-9]{4}|[0-9]{2}[0-9]{3}|[0-9]{3}[0-9]{2}|[0-9]{4}[0-9]
( | については【| OR(または)】で学習しました。)
後は、最初の 1桁 を 0 にして、加入者番号の 4桁 を付け足します。
すると、0(?:[0-9][0-9]{4}|[0-9]{2}[0-9]{3}|[0-9]{3}[0-9]{2}|[0-9]{4}[0-9])[0-9]{4} の形になります。
( ( )は【( ) グループを指定】で詳しく説明しました。)
そして -(ハイフン) の表示があるパターンにも対応するため -? を使用します。
全体では 0(?:[0-9]-?[0-9]{4}|[0-9]{2}-?[0-9]{3}|[0-9]{3}-?[0-9]{2}|[0-9]{4}-?[0-9])-?[0-9]{4} の形です。
但し、これも対象文字列の状態によりパターンを変化させます。
それでは、様々な対象文字列につき以下で検証してみましょう。
この記事の難度は、基礎 Cクラスです。
(A: やさしい → E: 難しい)
事前知識として、pythonから正規表現を扱う方法が必要になります。
また、正規表現における文字クラスや量指定子の知識も必要です。
この他に、先頭や末尾の位置を表す ^ $ 及び、\b (単語の境界) や先読み、後読みなどのアサーションを総合的に理解している事が望ましいです。
(不安な人でも、【Pythonから使う】【基礎1 文字クラス】【基礎5 量指定子】【基礎2 アサーション①】【基礎4 アサーション②】で詳しい解説があるので安心です。)
最初はシンプルなパターンで構成し、徐々にアサーションを使っていきましょう。
| 難度 : | |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。正規表現の文字クラスや繰り返し、アサーション等。 |
| 学習効果: | 電話番号のパターンを掴み、正規表現で取得する事が出来るようになる。 |
Contens | 目次
| Chapter1 | Pythonで実行 |
Chapter1 Pythonで実行
携帯電話 0[7-9]0[0-9]{8}
携帯電話から確認していきましょう。
まずは -(ハイフン) が無い、一番簡単な場合です。
文字列パターンは前述した 0[7-9]0[0-9]{8} を用います。
対象文字列を 09012345678 とした場合にはマッチするはずなので確認します。
re_prac2_1.py
import re
pattern = re.compile("0[7-9]0[0-9]{8}")
st = "09012345678"
result = pattern.search(st)
print("↓ 対象文字列\n"+st)
print(result)
実行結果
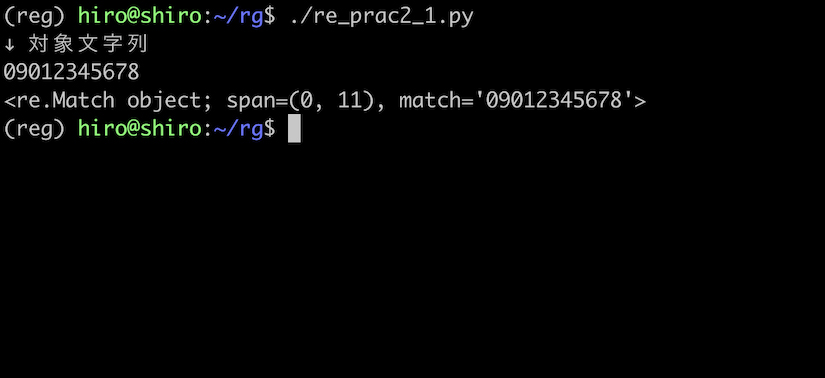
これは特に問題無いです。
次は対象文字列の2桁目を 9 から 1 に変更します。
マッチが起こらないのを確かめます。
re_prac2_2.py
import re
pattern = re.compile("0[7-9]0[0-9]{8}")
st = "01012345678"
result = pattern.search(st)
print("↓ 対象文字列\n"+st)
print(result)
実行結果
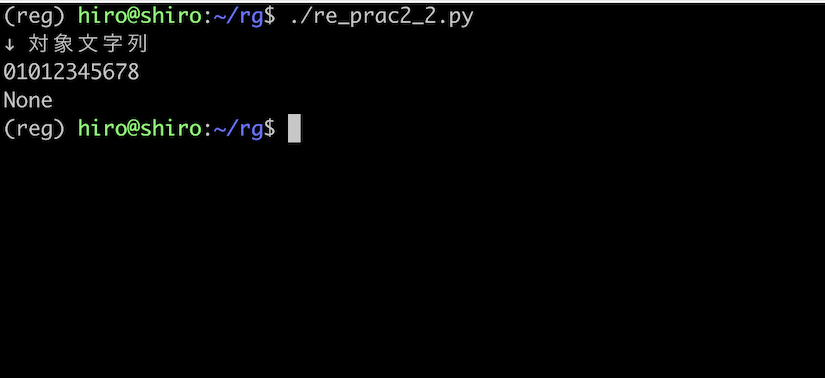
予想通りで問題は無いです。
では、対象文字列を1桁分余計に増やして、090123456789 にします。
この場合、12桁の番号になるので元来であれば弾いて欲しいところです。
re_prac2_3.py
import re
pattern = re.compile("0[7-9]0[0-9]{8}")
st = "090123456789"
result = pattern.search(st)
print("↓ 対象文字列\n"+st)
print(result)
実行結果
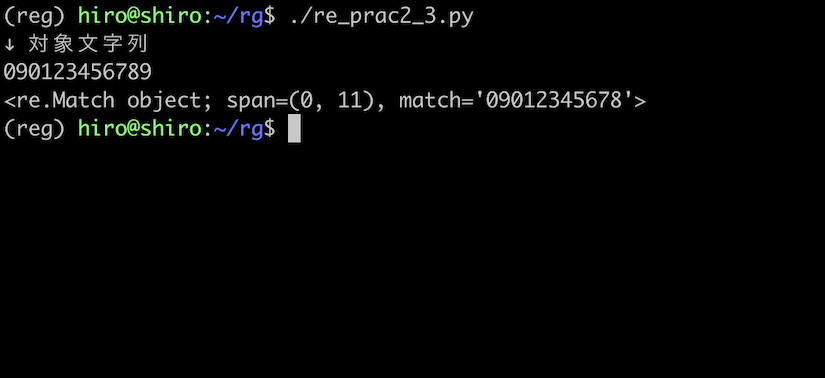
結果は12桁の番号(090123456789)の中で、11桁分(09012345678)までマッチしてしまいました。
これはあまり望ましい結果とは言えないので、12桁の番号は弾くようにします。
^0[7-9]0[0-9]{8}$
11桁分だけをマッチの対象にするには、^ $ を使います。
^ $ は、それぞれ行の先頭、文字列の末尾を表します。
ゆえに、0[7-9]0[0-9]{8} の両端を ^ と $ で挟んで ^0[7-9]0[0-9]{8}$ にすれば、先頭から末尾までで11桁の数字を指定できます。
(^ や $ については【^ 行の先頭】及び、【$ 文字列の末尾】で詳しく説明しています。)
先程の re_prac2_3.py の文字列パターンを変更して再度実行します。
re_prac2_4.py
import re
pattern = re.compile("^0[7-9]0[0-9]{8}$")
st = "090123456789"
result = pattern.search(st)
print("↓ 対象文字列\n"+st)
print(result)
実行結果
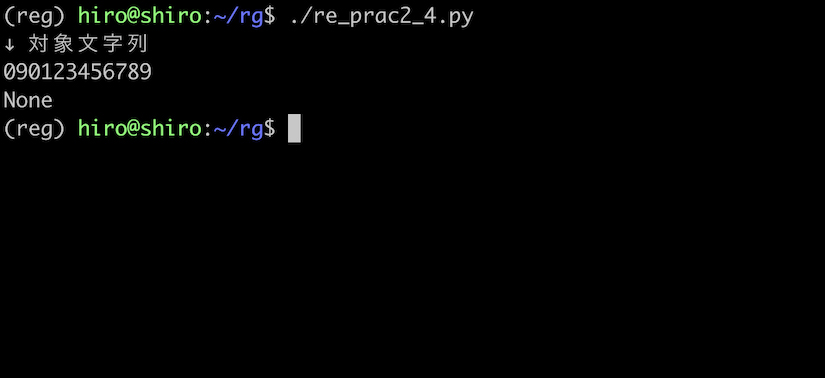
今度はしっかり弾きました。
^0[7-9]0-[0-9]{4}-[0-9]{4}$
次は -(ハイフン) がある場合を確認します。
文字列パターンを ^0[7-9]0-[0-9]{4}-[0-9]{4}$ に修正します。
re_prac2_5.py
import re
pattern = re.compile("^0[7-9]0-[0-9]{4}-[0-9]{4}$")
st = "090-1234-5678"
result = pattern.search(st)
print("↓ 対象文字列\n"+st)
print(result)
実行結果
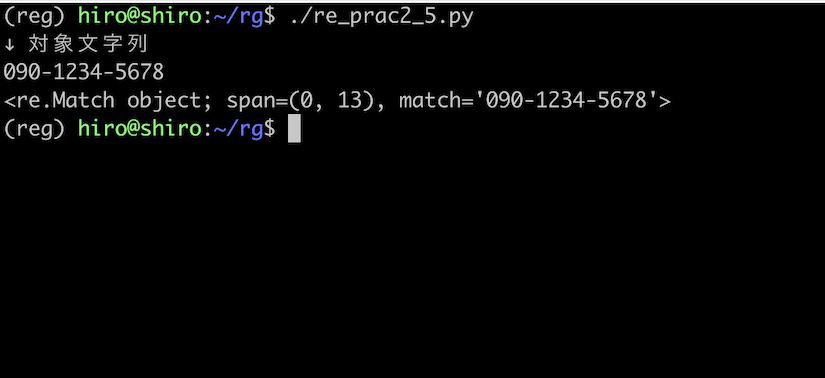
-(ハイフン) に対応している事を確認できました。
しかしこの場合だと、-(ハイフン) が無い場合にマッチしないので、-(ハイフン) を省略可能な形に直します。
^0[7-9]0-?[0-9]{4}-?[0-9]{4}$
文字列パターンを ? を用いて ^0[7-9]0-?[0-9]{4}-?[0-9]{4}$ のように直します。
対象文字列は、-(ハイフン) がある番号と無い番号を混ぜて 09012345678 090-1234-5678 にしてみましょう。
re_prac2_6.py
import re
pattern = re.compile("^0[7-9]0-?[0-9]{4}-?[0-9]{4}$")
st = "09012345678 090-1234-5678"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
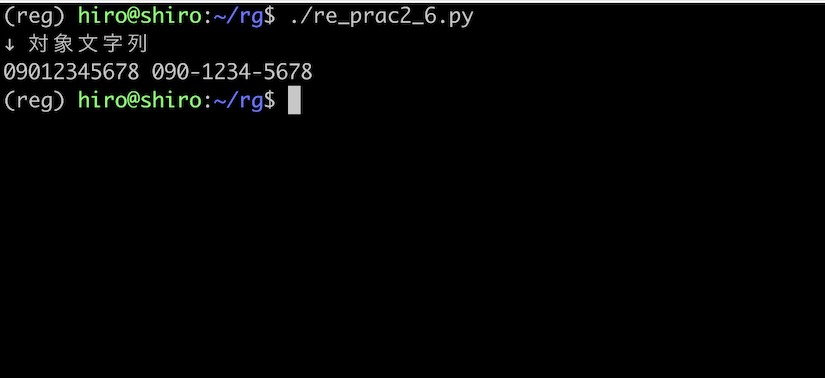
2つの番号は各々パターンを満たしていますが、どれもマッチしていません。
^ と $ の制約が影響するからです。
そこで、^ と $ の代わりに \b を使う事でこの結果を回避できそうです。
\b0[7-9]0-?[0-9]{4}-?[0-9]{4}\b
\b は、単語の境目にマッチする正規表現であり、\w と \W との間、あるいは \w と文字列の先頭・末尾との間でのマッチを引き起こします。
(\b については、【\b 単語の境界】で詳しく説明しています。)
パターンである 0[7-9]0-?[0-9]{4}-?[0-9]{4} を \b で挟んで、\b0[7-9]0-?[0-9]{4}-?[0-9]{4}\b のようにしましょう。
これで番号が複数個ある場合でも拾えるはずです。
re_prac2_7.py
import re
pattern = re.compile(r"\b0[7-9]0-?[0-9]{4}-?[0-9]{4}\b")
st = "09012345678 090-1234-5678 090123456789"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
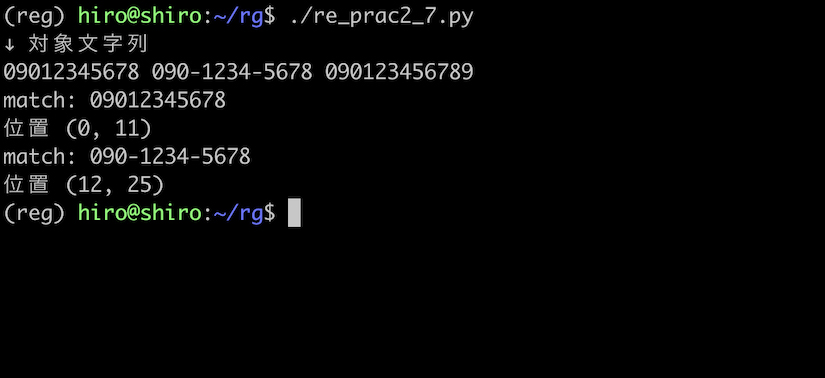
狙い通り、パターンの構成要件を満たしている番号のみ(09012345678 090-1234-5678)を拾えました。
さらに、前回の【クレジットカード番号】編と同様に、番号の前後に単語構成文字以外の余計な - や : などが付いているケースを検証してみましょう。
(?<!-)\b0[7-9]0-?[0-9]{4}-?[0-9]{4}\b(?!:)
パターンは \b0[7-9]0-?[0-9]{4}-?[0-9]{4}\b のままで、電話番号が -090-1234-5678 や 09012345678: を含むような場合について実行してみます。
re_prac2_8.py
import re
pattern = re.compile(r"\b0[7-9]0-?[0-9]{4}-?[0-9]{4}\b")
st = "09012345678 -090-1234-5678 09012345678:"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
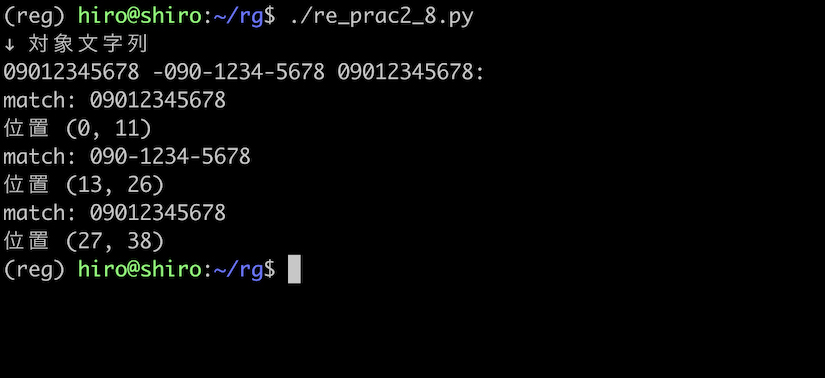
実行結果(続き)
前後に - や : が付いている番号までマッチしました。
元来であれば、何も付いていない番号に一致させたいので、これは否定したい結果です。
この問題に対処するには、否定後読みや否定先読みを用います。
パターン前後に (?<!-) (?!:) を挟んで (?<!-)\b0[7-9]0-?[0-9]{4}-?[0-9]{4}\b(?!:) にします。
こうする事で、番号の前後に - や : のある形式は不一致になるはずです。
(否定後読みについては、【(?<! ) 否定後読み】で、否定先読みについては、【(?! ) 否定先読み】で詳しく説明しています。)
re_prac2_9.py
import re
pattern = re.compile(r"(?<!-)\b0[7-9]0-?[0-9]{4}-?[0-9]{4}\b(?!:)")
st = "09012345678 -090-1234-5678 09012345678:"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
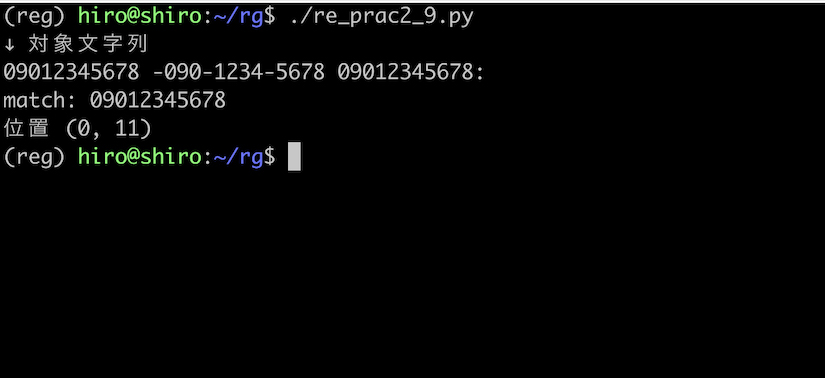
きちんと、適切な形式の番号だけに一致しました。
(?<![+#-])\b0[7-9]0-?[0-9]{4}-?[0-9]{4}\b(?![:*@])
先程は、番号の前後に - と : しか余計な記号はありませんでしたが、もう少し不要な記号がある場合にも対応してみましょう。
それには、先読みや後読みと文字クラスを組み合わせます。
例えば、+ # - の付いた番号はマッチの対象から外したいなら、+ # - を集合にして [+#-] とし、後は否定後読みなどに付加して (?<![+#-]) の形にします。
下の re_prac2_10.py では、番号の前後に様々な不必要な記号がありますが、これらを弾くパターンを構成しています。
re_prac2_10.py
import re
pattern = re.compile(r"(?<![+#-])\b0[7-9]0-?[0-9]{4}-?[0-9]{4}\b(?![:*@])")
st = "09012345678 -090-1234-5678 09012345678:"\
"\n" "#08012345679@ +07012345677 07012345672"\
"\n" "09012345676* -09012345671"
print("↓ 対象文字列\n"+st+"\n↑ 対象文字列")
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
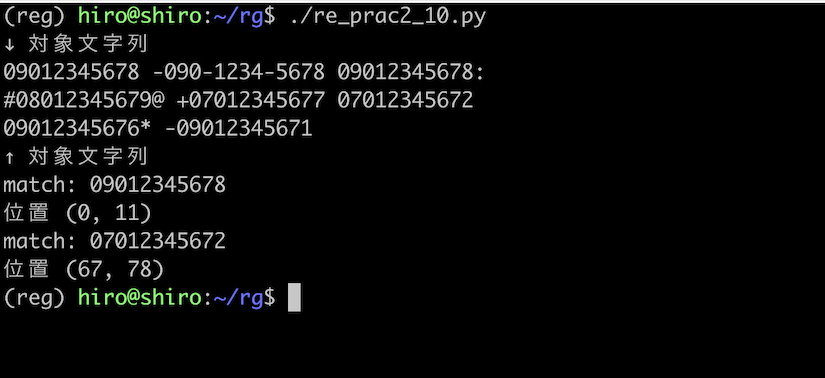
実行結果(続き)
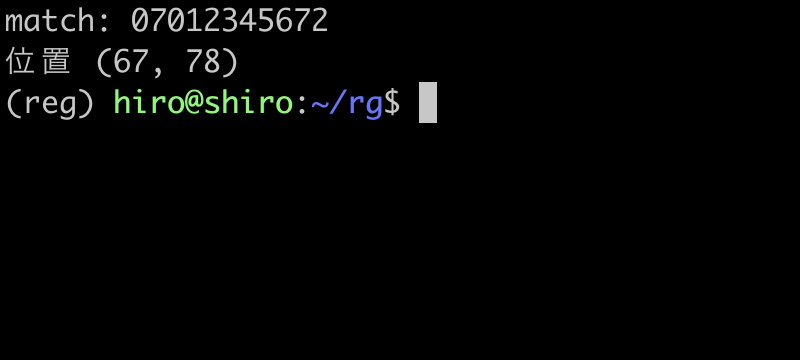
無事に 09012345678 と 07012345672 のみマッチさせる事が出来ました。
固定電話
0(?:[0-9]-?[0-9]{4}|[0-9]{2}-?[0-9]{3}|[0-9]{3}-?[0-9]{2}|[0-9]{4}-?[0-9])-?[0-9]{4}
今度は、固定電話を検証しましょう。
- (ハイフン) がある場合にも、無いときにも対応します。
要するに- (ハイフン) は省略できるので ? を用いて文字列パターンは、0(?:[0-9]-?[0-9]{4}|[0-9]{2}-?[0-9]{3}|[0-9]{3}-?[0-9]{2}|[0-9]{4}-?[0-9])-?[0-9]{4} にします。
re_prac2_12.py
import re
pattern = re.compile("0(?:[0-9]-?[0-9]{4}|[0-9]{2}"\
"-?[0-9]{3}|[0-9]{3}-?[0-9]{2}"\
"|[0-9]{4}-?[0-9])-?[0-9]{4}")
st = "03-3100-5678 0112001234 01392-2-5678"\
"\n" "0-12345-678 1123456789"
print("↓ 対象文字列\n"+st+"\n↑ 対象文字列")
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
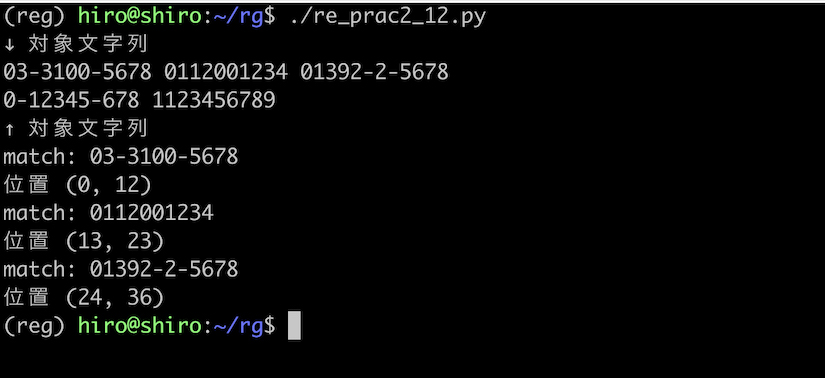
実行結果(続き)
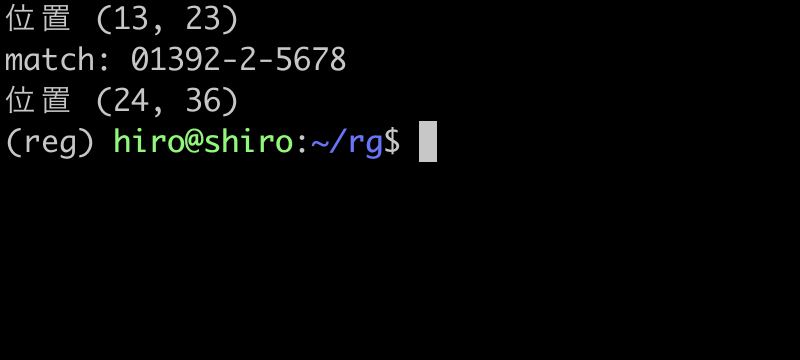
これも問題なくパターンを満たす番号のみ取得しています。
後は携帯電話と同様な修正を行い、番号の前後に不要な記号がある場合まで対応します。
(?<![+#-])\b0(?:[0-9]-?[0-9]{4}|[0-9]{2}-?[0-9]{3}|[0-9]{3}-?[0-9]{2}|[0-9]{4}-?[0-9])-?[0-9]{4}\b(?![:*@])
re_prac2_13.py
import re
pattern = re.compile(r"(?<![+#-])\b0(?:[0-9]-?[0-9]{4}|[0-9]{2}"\
"-?[0-9]{3}|[0-9]{3}-?[0-9]{2}"\
r"|[0-9]{4}-?[0-9])-?[0-9]{4}\b(?![:*@])")
st = "03-3100-5678 0112001234 01392-2-5678"\
"\n" "#098-800-4567 -075-861-7890@ +0452009876"\
"\n" "052-200-3456* -06-4250-2345 01120012345"
print("↓ 対象文字列\n"+st+"\n↑ 対象文字列")
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
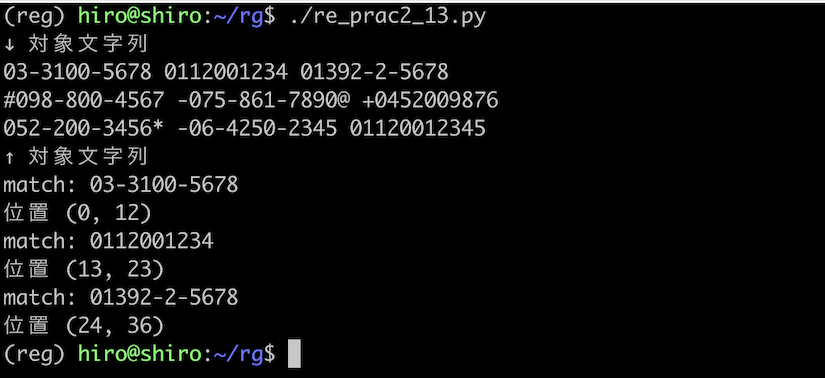
実行結果(続き)
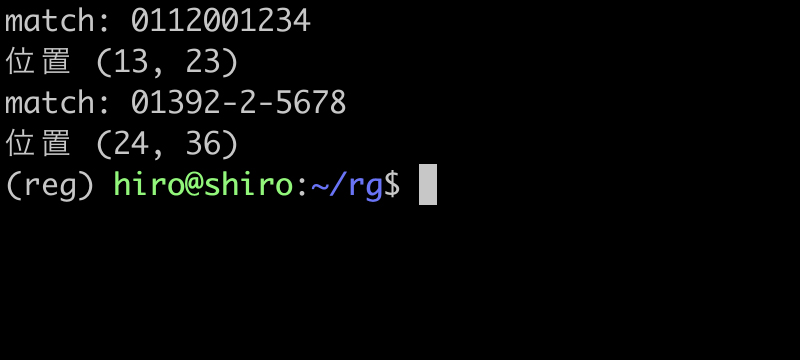
不要な記号がある場合など、パターンに合致しない番号はマッチしていません。
電話番号編の説明は以上です。
電話番号のパターンを掴み、正規表現で取得する事が出来るようになりました。
なお電話番号のパターンは、今回紹介した以外にも様々な法則が潜んでいます。
最後まで読めた聡明な読者ならば、必ずそれらにも対応できる能力があります。
技術を高めるチャンスとして挑んで下さい。
それでは!
関連記事

クレジットカード番号
| 正規表現: | 定形の数字形式 |
| 難度 : | 基礎 |
| 事前知識: | Pythonと正規表現の基礎。文字クラス等。 |
| 学習効果: | クレジットカードのパターンを掴み、正規表現で取得する事が出来るようになる。 |

電話番号
| 正規表現: | 定形の数字形式 |
| 難度 : | 基礎 |
| 事前知識: | Pythonと正規表現の基礎。文字クラス等。 |
| 学習効果: | 電話番号のパターンを掴み、正規表現で取得する事が出来るようになる。 |

正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |