正規表現基礎
\b 単語の境界
カテゴリー:アサーション②

\w と \W の間で ...
さて、ここからは以前説明した言明(アサーション) の続きになります。
アサーションは文字そのものではなく、位置にマッチする正規表現でした。
位置の中でも単語の境目にマッチする正規表現が \b です。
単語の境界とは、 \w と \W との間、あるいは \w と文字列の先頭・末尾との間のことです。
(\w、\W については【\w 単語構成文字】、【\W 単語構成文字以外】で詳しく説明しています。)
単語の境界のイメージ

また、単語とは単語文字の並びとして定義されていますが、何を単語構成文字とするかはフラグの影響を受けます。
以下で平易な例を挙げながら解説していきます。
この記事の難度は、基礎 Cクラスです。
(A: やさしい → E: 難しい)
事前知識として、pythonから正規表現を扱う方法が必要になります。
また、正規表現における文字クラスの知識を理解していると、スムーズに読み進められます。
(不安な人でも、【Pythonから使う】【基礎1 文字クラス】で詳しい解説があるので安心です。)
| 難度 : | |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。正規表現の文字クラス等。 |
| 学習効果: | 単語の境界とされる位置を的確に認識できるようになる。また、フラグによる単語構成文字の範囲の変化についても、適切に扱える。 |
Contens | 目次
| Chapter1 | Pythonで実行 |
Chapter1 Pythonで実行
raw文字列記法
\b は後退 (BackSpace)を表します。
それ故に、パターンの指定でraw文字列記法を用いない場合、BackSpaceに対するマッチになります。
(raw文字列記法 については【\ エスケープ文字の働き】で詳しく説明しています。)
re_meta18_1.py
import re
pattern = re.compile("\b")
st = "\b"
result = pattern.search(st)
print("st=",st)
print(result)
実行結果
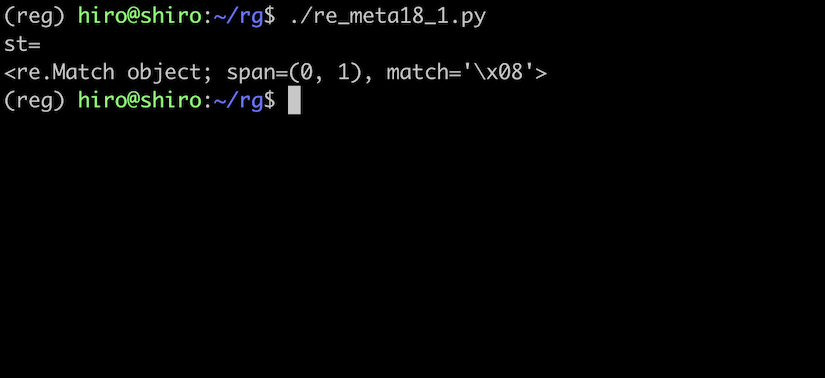
BackSpaceにマッチしています。
では、raw文字列記法を使います。
re_meta18_2.py
import re
pattern = re.compile(r"\b")
st = "\b"
result = pattern.search(st)
print("st=",st)
print(result)
実行結果
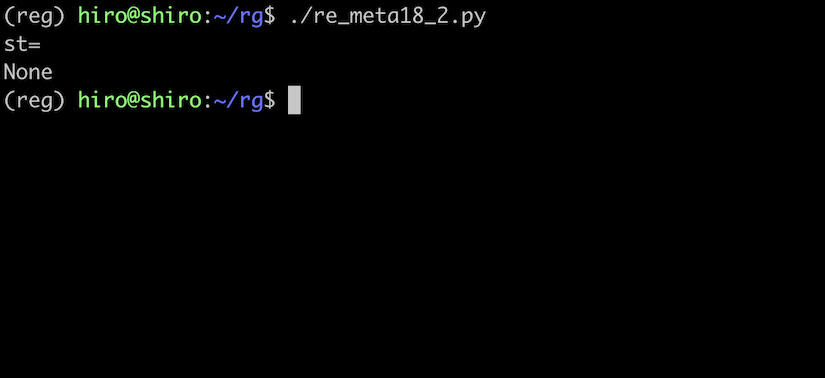
BackSpaceに一致しなくなりました。
\w と先頭・末尾との境界
対象文字列が a の場合、\b のマッチ箇所は、a と先頭の境界、または a と末尾の境界になります。
re_meta18_3.py
import re
pattern = re.compile(r"\b")
st = "a"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
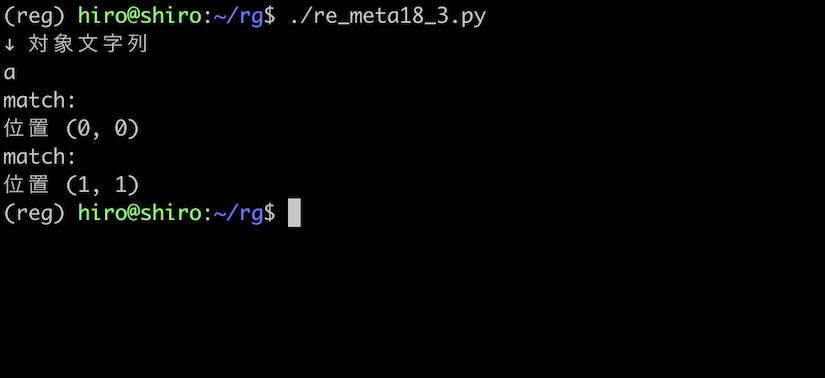
予想通り a の先頭と末尾の間に一致しました。
\w と \W の境目、及び \w と先頭・末尾との境界
対象文字列を A C とします。
この場合、\b のマッチ箇所は、A と先頭の境界、または C と末尾の境界があります。
さらに A とスペース、スペースと C との境目も加わります。
re_meta18_4.py
import re
pattern = re.compile(r"\b")
#AとCの間は半角スペース
st = "A C"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
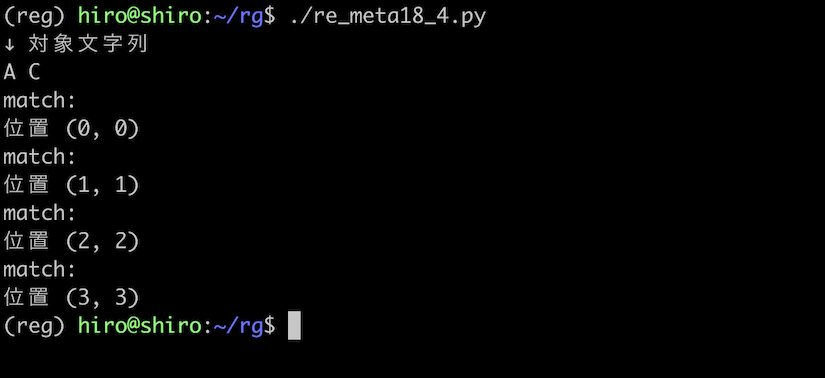
各々の境目を確認出来ました。
なお、AとCの間をスペースでなく ! にしても同様な結果が発生します。
! は \w に含まれる単語構成文字ではないからです。
re_meta18_5.py
import re
pattern = re.compile(r"\b")
st = "A!C"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
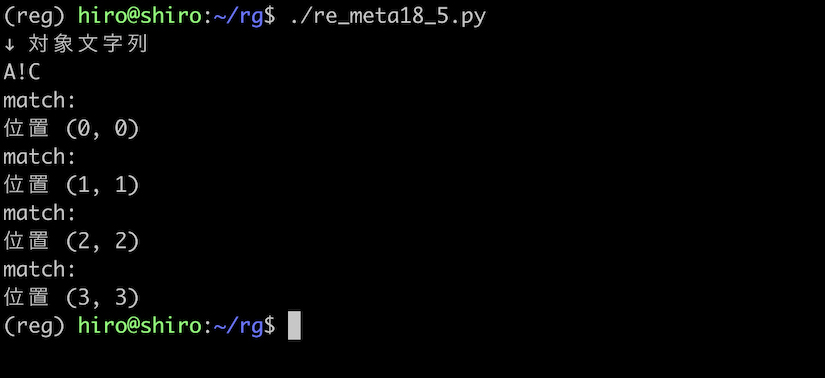
meta18_4.py と等しい結果です。
\b[A-Z]\b
今度は、\b だけでなく単語と組み合わせてみます。
re_meta18_6.py
import re
pattern = re.compile(r"\b[A-Z]\b")
#MとAの間、AとPの間は半角スペース
st = "M A P"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
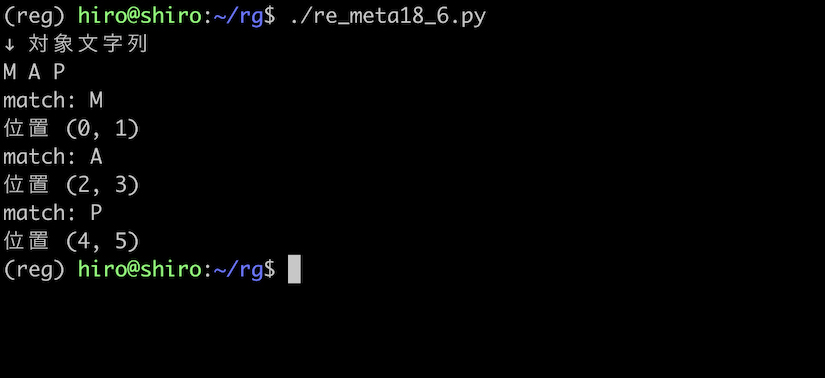
M, A, P は各々 \b に囲まれているので一致しています。
もう一つ例として、\b で囲まれている数字をマッチさせます。
re_meta18_7.py
import re
pattern = re.compile(r"\b\d\b")
# y と 2 の間、2 と 例 の間は半角スペース
st = "1day 2 例3"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
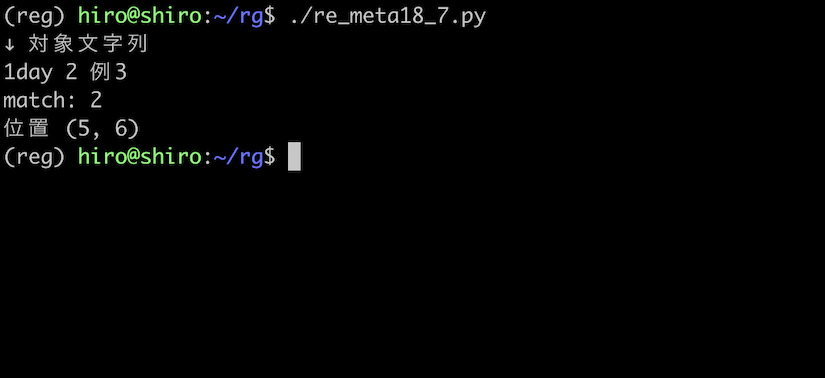
1 や 3 は、隣に単語構成文字があるのでマッチしていません。
ASCIIフラグ
【\w 単語構成文字】で詳しく説明したように、単語構成文字の範囲はフラグの有無により変化します。
フラグの無い状態だと、漢字なども \w の範囲に含まれます。
故に、meta18_7.py では数字の前にある漢字も \w に該当し、その結果としてその後に続く数字は \b に囲まれている状態にはなっていませんでした。
範囲を狭めて漢字を \W として扱うには、ASCIIフラグを用いれば可能になります。
re_meta18_8.py
import re
pattern = re.compile(r"\b\d\b",flags=re.ASCII)
# y と 2 の間、2 と 例 の間は半角スペース
st = "1day 2 例3"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
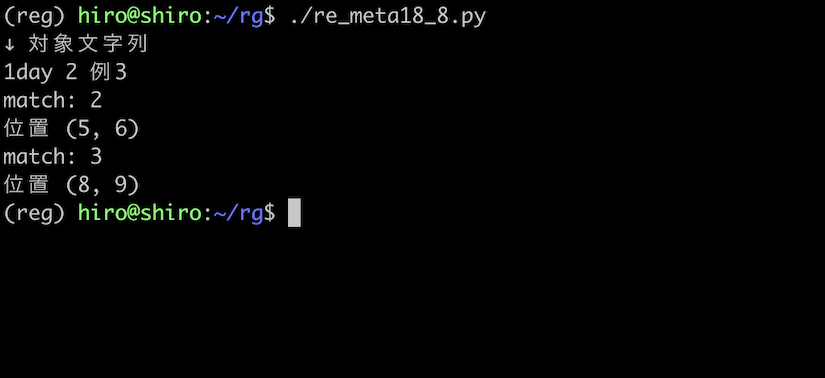
フラグを付けた事で 3 もマッチするようになりました。
アイス(ice)にマッチ
もう少し例を出しましょう。
ice という単語にマッチさせます。
re_meta18_9.py
import re
pattern = re.compile(r"\bice\b")
st = "icebox ice dice licence"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
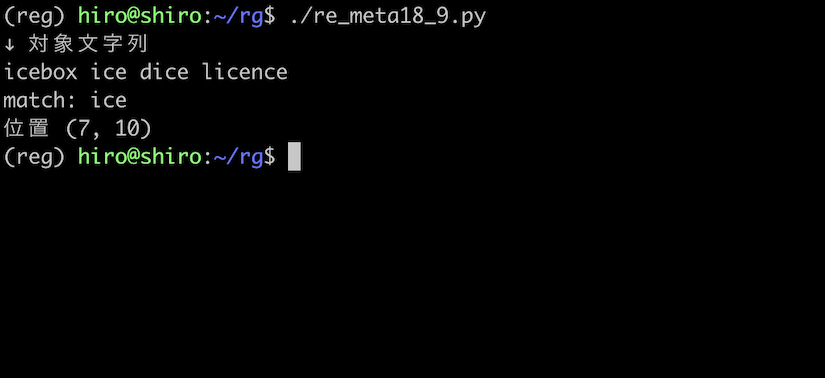
アイス(ice)を取得出来ました。
単語の境界を表す \b についてはここまでです。
多くの例を取り扱ったので、単語の境界とされる位置を的確に認識できるようになりました。
また、フラグによる単語構成文字の範囲の変化について、適切に扱うことを覚えました。
関連記事

\b 単語の境界
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラス等。 |
| 学習効果: | 単語の境界とされる位置を的確に認識できるようになる。 |

\B 単語の境界でない
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラス等。 |
| 学習効果: | 単語の境界でない位置を的確に認識できるようになる。 |

(?= ) 先読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 先読みの性質である、任意に設定したパターンの前にマッチする、という事を理解出来る。 |

(?<= ) 後読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 後読みの性質である、任意に設定したパターンの後にマッチする、という事を理解出来る。 |

(?! ) 否定先読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 否定先読みの性質である、任意に設定したパターン以外の前でマッチする、という事を理解出来る。 |

(?<! ) 否定後読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 否定後読みの性質である、任意に設定したパターン以外の後でマッチする、という事を理解出来る。 |

正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |