正規表現基礎
(?<= ) 後読み
カテゴリー:アサーション②

指定文字と1つ後の間で ...
後読みは、任意に設定したパターンの後にマッチする正規表現です。
前回紹介した先読みとは、ちょうど逆の位置になります。
表記は (?<= ) のようになります。
先読み(?= )の記述方法に似ていますが、後読みは < が必要になります。
例えば、(?<=¥) ならば ¥ とその後にある文字の間にマッチが生じます。
対象文字列が ¥5 €5 の場合

先読みとの違いを示す為に、もう一つ例を挙げます。
指定する文字を a とするならば、先読みは (?=a),後読ならば、(?<=a) となります。
このパターンに対して、対象文字列が map の場合、下の図のように各々マッチします。
対象文字列が map の場合

この他に注意点として、後読みに指定する任意のパターンに、量指定子は利用出来ない点があります。
(量指定子 については【基礎5 量指定子】で詳しく説明します。)
先読みのときと同様に、シンプル、且つ最小構成な例を使い解説します。
この記事の難度は、基礎 Cクラスです。
(A: やさしい → E: 難しい)
事前知識として、pythonから正規表現を扱う方法が必要になります。
また、正規表現における文字クラスの知識や、選択を表す正規表現である | OR(または) を理解している事が望ましいです。
(不安な人でも、【Pythonから使う】【基礎1 文字クラス】 【| OR(または)】、で詳しい解説があるので安心です。)
シンプルな例を一個ずつ確認する事で、後読みに慣れていきます。
また、先読みとの違いを意識しましょう。
| 難度 : | |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。正規表現の文字クラスや選択等。 |
| 学習効果: | 後読みの性質である、任意に設定したパターンの後にマッチする、という事を理解出来る。 |
Contens | 目次
| Chapter1 | Pythonで実行 |
Chapter1 Pythonで実行
(?<=a)
先ず上記した例ですが、文字列パターンが (?<=a) の場合を考えます。
これは、a とその後にある文字の間にマッチします。
対象文字列が map なら a とその後にある p の間です。
re_meta21_1.py
import re
pattern = re.compile("(?<=a)")
st = "map"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
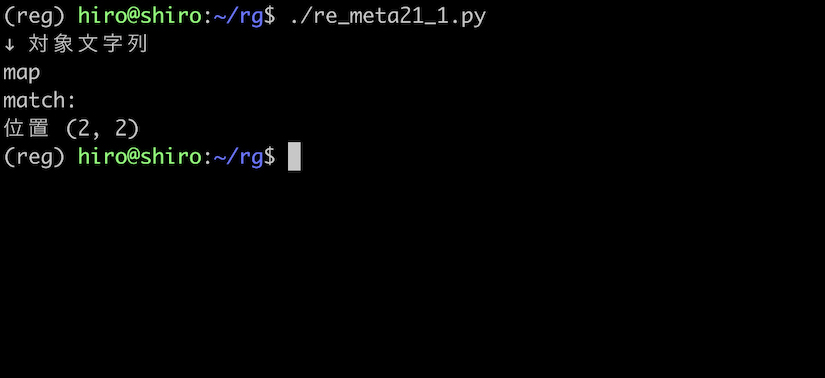
予想通り、a と p の間にマッチしました。
a を先頭や末尾にも並べて、 aaa のようにして実行してみます。
各々 a の後にヒットするはずです。
re_meta21_2.py
import re
pattern = re.compile("(?<=a)")
st = "aaa"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
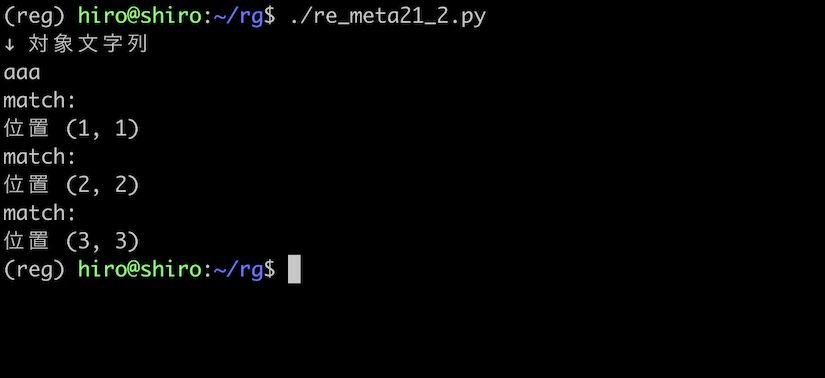
これも想定通りの結果です。
次に空白を挟んで、a a を対象文字列とします。
re_meta21_3.py
import re
# a と a の間は半角スペース
pattern = re.compile("(?<=a)")
st = "a a"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
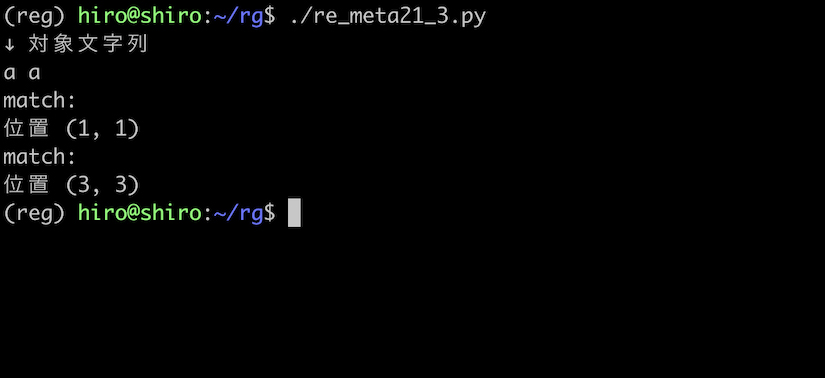
スペースが存在しても、a の後にマッチするという性質は変わりません。
もう一つ例を挙げます。
文字列パターンが (?<=t) であり、対象文字列を teetotalism とする場合です。
re_meta21_4.py
import re
pattern = re.compile("(?<=t)")
st = "teetotalism"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
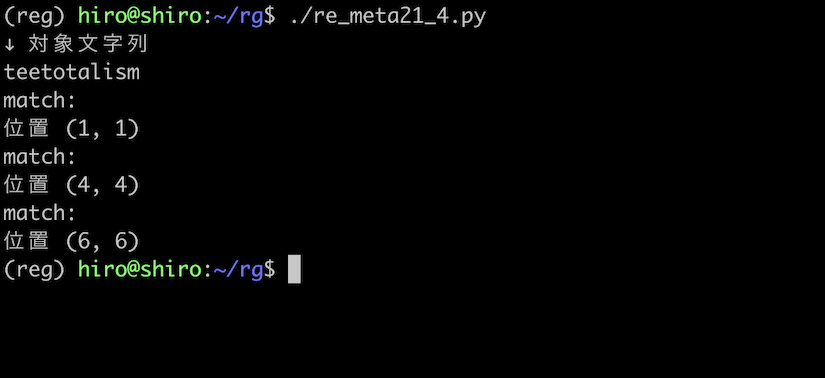
それぞれ t の後にマッチしています。
今度は、(?<=t) だけでなく単語と組み合わせて使ってみます。
(?<=t)a
対象文字列は、meta21_4.py と同様に teetotalism とします。
但し、文字列パターンを (?<=t)a とする事で、t の後にある a という文字にマッチします。
re_meta21_5.py
import re
pattern = re.compile("(?<=t)a")
st = "teetotalism"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
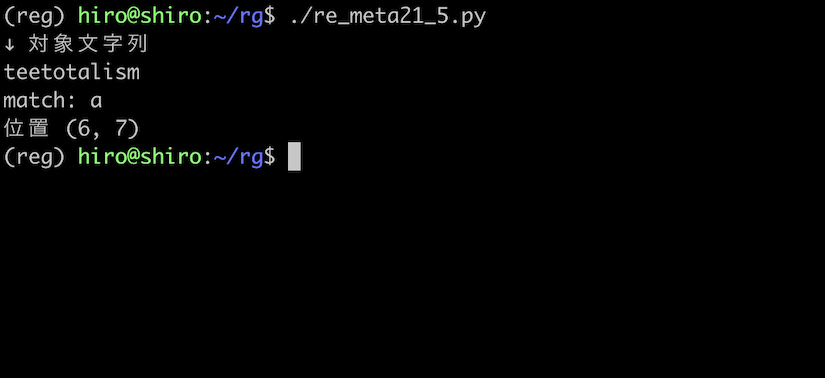
狙い通り、a という文字に一致しました。
次の例では、通貨記号が ¥ である数字を取得します。
re_meta21_6.py
import re
pattern = re.compile("(?<=¥)\d")
st = "¥5 3元 1¥ $9 £8 €7"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
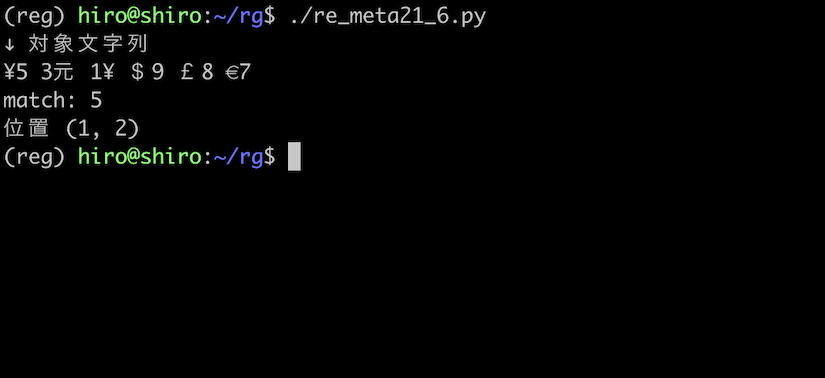
¥ 記号の後の数字を取得出来ました。
メタキャラクタと組み合わせて、¥ の他に € の値もその対象にします。
(?= | )
選択(OR)を表す正規表現は | です。
(| については【| OR(または)】で詳しく説明しています。)
(?<=¥|€)\d のようにすると、¥ の他に € の後にある数字にマッチします。
re_meta21_7.py
import re
pattern = re.compile("(?<=¥|€)\d")
st = "¥5 3元 1¥ $9 £8 €7"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
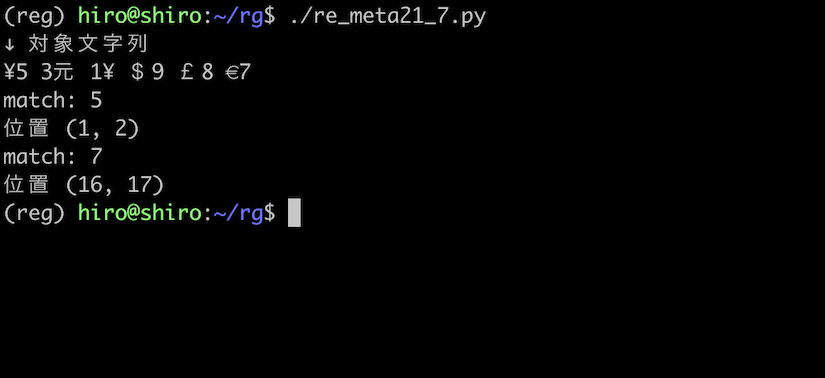
5円の他に€7を得られました。
(?<= | ) のように、後読みと | を併用する場合の注意点として、選択(OR)の対象になる文字数が異なるとエラーが発生する事です。
例えば (?<=令和|R) のような場合です。
re_meta21_8.py
import re
pattern = re.compile("(?<=令和|R)")
st = "8年 令和2年 R3年 平成5年"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
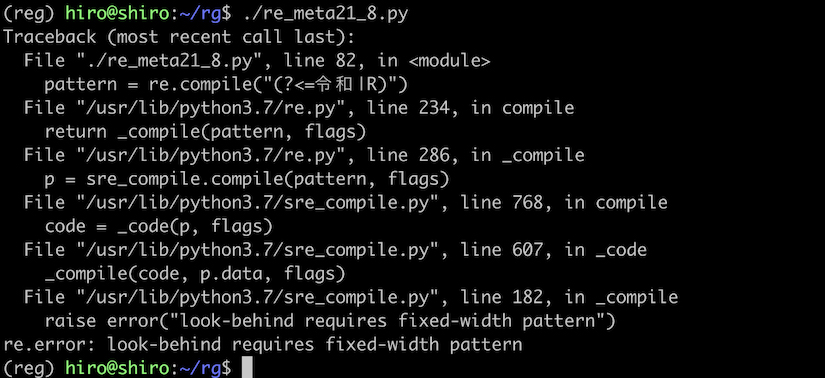
look-behind requires fixed-width pattern のエラーが発生しました。
これを回避するには、((?<=令和)|(?<=R)) のように変更します。
re_meta21_9.py
import re
pattern = re.compile("((?<=令和)|(?<=R))\d")
st = "8年 令和2年 R3年 平成5年"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
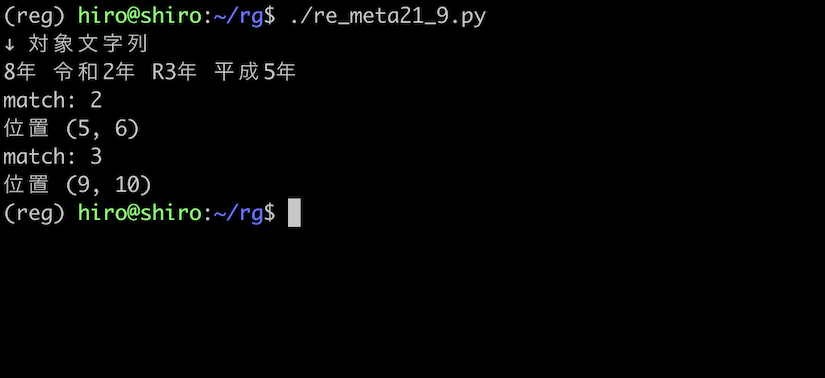
無事にエラーの発生を避けられました。
似たような場合として、(?<=^|R) のような文字列パターンもエラーが生じます。
re_meta21_10.py
import re
pattern = re.compile("(?<=^|R)")
st = "8年 令和2年 R3年 平成5年"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
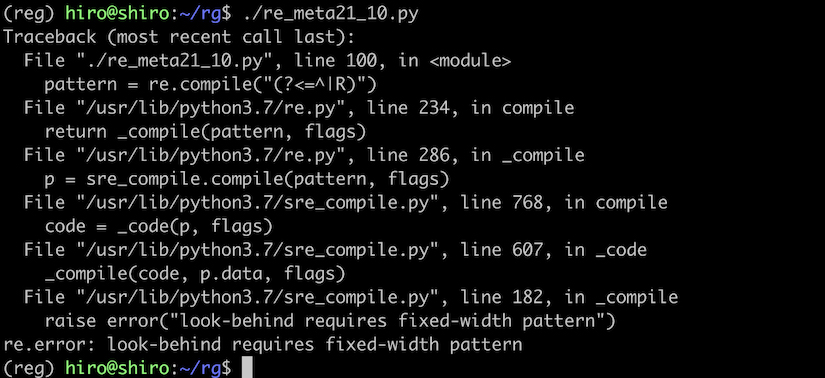
このエラーの回避も、meta21_9.py と同様です。
re_meta21_11.py
import re
pattern = re.compile("((?<=^)|(?<=R))\d")
st = "8年 令和2年 R3年 平成5年"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
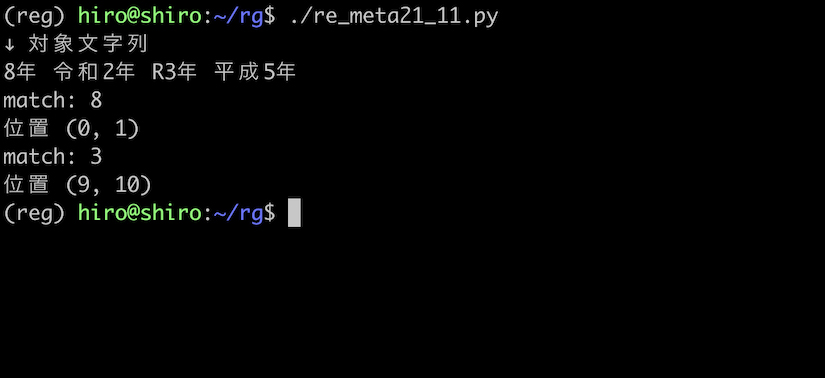
問題無く処理できました。
また、後読みに指定する任意のパターンに、量指定子は利用出来ません。
(量指定子 については【基礎5 量指定子】で詳しく説明します。)
それ故に、(?<=\w*) とした場合にはエラーが発生します。
re_meta21_12.py
import re
pattern = re.compile("(?<=\w*)\d")
st = "28年 令和2年 R3年 平成15年"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
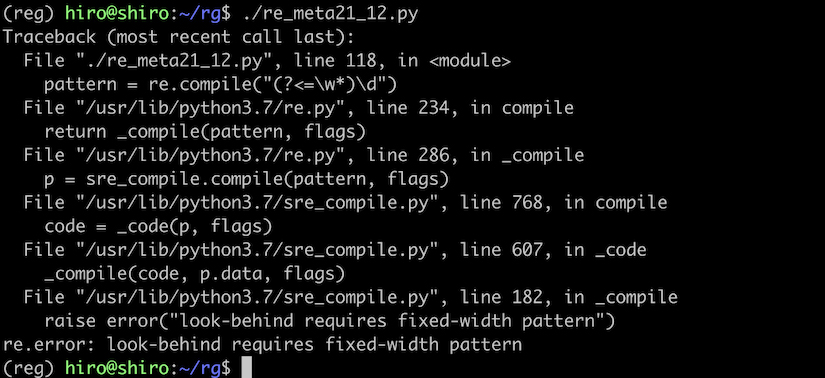
look-behind requires fixed-width pattern のエラーです。
さて、この他にも ^ を使ってみます。
^ は、文字列の先頭を意味します。
(^ については【^ 行の先頭】で詳しく説明しています。)
先頭の金額を抽出するには、以下のようにします。
re_meta21_13.py
import re
pattern = re.compile("(?<=^¥)\d")
st = "¥2 ¥9 1¥ ¥0"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
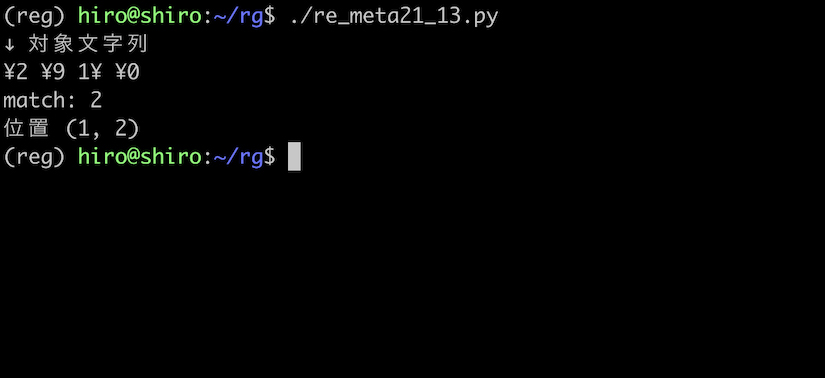
¥9 や ¥0 ではなく、¥2を対象にできました。
続けて例を出します。
. の後にある数字を狙います。
. はそのまま使うと任意の1文字になってしまうので、\ (バックスラッシュ)と併用します。
(\ については【\ エスケープ文字の働き】で詳しく説明しています。)
re_meta21_14.py
import re
pattern = re.compile("(?<=\.)\d")
st = "7.8 21.6 a.m"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
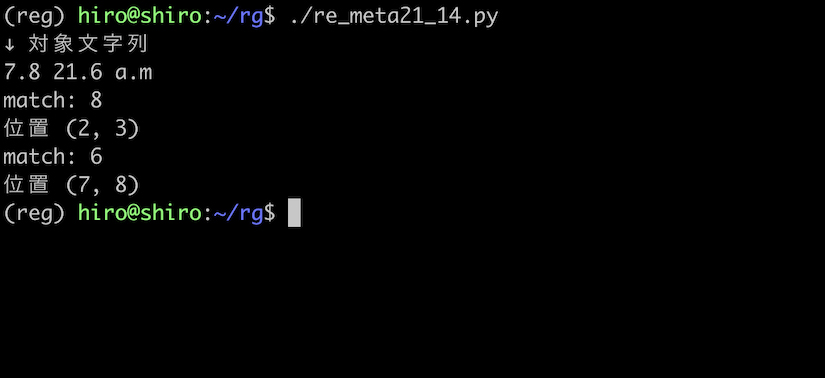
. の後にある数字のみを取得出来ました。
後読みの説明はここで終了です。
多くの例をみてきたので、後読みの性質である、任意に設定したパターンの後にマッチする、という事を理解出来ました。
これにより、取得したい部分が、ある文字列の後にある場合に役立つでしょう。
関連記事

\b 単語の境界
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラス等。 |
| 学習効果: | 単語の境界とされる位置を的確に認識できるようになる。 |

\B 単語の境界でない
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラス等。 |
| 学習効果: | 単語の境界でない位置を的確に認識できるようになる。 |

(?= ) 先読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 先読みの性質である、任意に設定したパターンの前にマッチする、という事を理解出来る。 |

(?<= ) 後読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 後読みの性質である、任意に設定したパターンの後にマッチする、という事を理解出来る。 |

(?! ) 否定先読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 否定先読みの性質である、任意に設定したパターン以外の前でマッチする、という事を理解出来る。 |

(?<! ) 否定後読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 否定後読みの性質である、任意に設定したパターン以外の後でマッチする、という事を理解出来る。 |

正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |