正規表現基礎
\B 単語の境界でない
カテゴリー:アサーション②

アレ や コレ の間で ...
前回では、単語の境目にマッチする正規表現である \b を紹介しました。
今回は b を大文字にした \B についての説明です。
\B も、\b と同様に位置にマッチする正規表現です。
どの位置かというと、\b とは逆で現在の位置が単語の境界でないときです。
単語の境界でない位置とは、\w と \w 、\W と \W 、あるいは \W と文字列の先頭・末尾との間のことです。
(\w、\W については【\w 単語構成文字】、【\W 単語構成文字以外】で詳しく説明しています。)
単語の境界でない位置のイメージ

なお、\b のときと同様に、何を単語構成文字とするかはフラグの影響を受けます。
それぞれの場合を簡単な例で説明していきます。
この記事の難度は、基礎 Cクラスです。
(A: やさしい → E: 難しい)
事前知識として、pythonから正規表現を扱う方法が必要になります。
また、正規表現における文字クラスの知識や、置換処理を理解している事が望ましいです。
(不安な人でも、【Pythonから使う】【基礎1 文字クラス】で詳しい解説があるので安心です。)
多くの例を検証していきながら、漠然としがちな \B の性質を捉えていきます。
| 難度 : | |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。正規表現の文字クラスや置換処理等。 |
| 学習効果: | 単語の境界でない位置を的確に認識できるようになる。また、フラグによる単語構成文字の範囲の変化についても、適切に扱える。 |
Contens | 目次
| Chapter1 | Pythonで実行 |
Chapter1 Pythonで実行
\w と \w の間
それでは、\B が \w と\w の間にマッチする事からみていきます。
対象文字列が map ならば、m と a の間あるいは、 a と p の間にマッチするはずです。
re_meta19_1.py
import re
pattern = re.compile(r"\B")
# \w と \w の間
st = "map"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
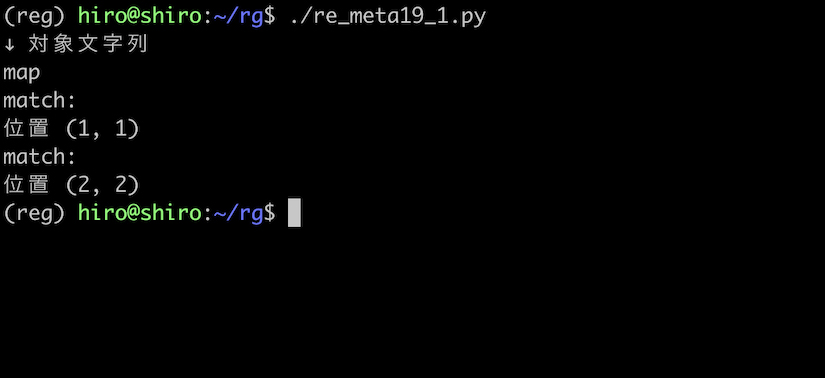
予想通りの位置に一致しました。
今度は、\B だけでなく単語と組み合わせてみます。
evidence という e が三つある文字列に対し、文字に囲まれた e のみを取得します。
re_meta19_2.py
import re
pattern = re.compile(r"\Be\B")
st = "evidence"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
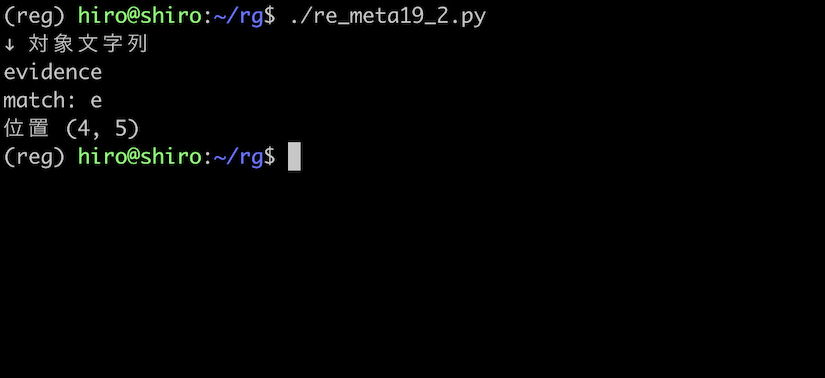
三つある e の中で、単語構成文字に囲まれた e のみがマッチしました。
もう少し例を挙げます。
数字の中で、文字に囲まれているものだけを狙います。
re_meta19_3.py
import re
pattern = re.compile(r"\B\d\B")
st = "1月 第2回 A3 4"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
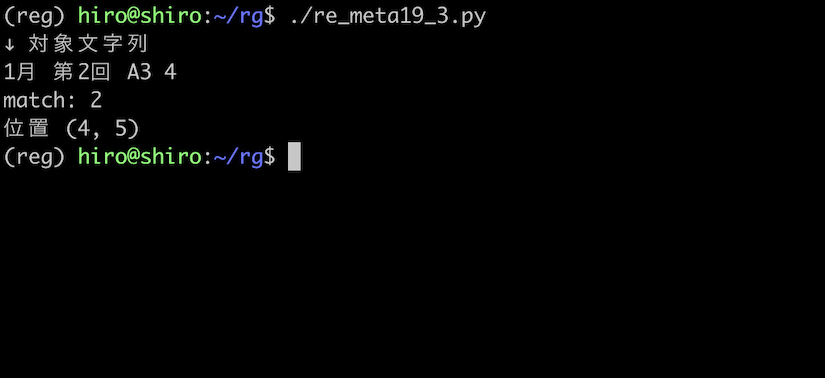
フラグが無い状態だと、漢字も単語構成文字になるので 2 はヒットしました。
先頭と\Wの間、\W と末尾の間
次は、\W と文字列の先頭・末尾との間のマッチについてです。
\W の例を半角スペースとします。
この半角スペースと先頭、末尾の境目に対して、 \B がマッチする事を確かめてみます。
re_meta19_4.py
import re
pattern = re.compile(r"\B")
# 先頭と \W の間、\W と末尾の間
st = " "
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
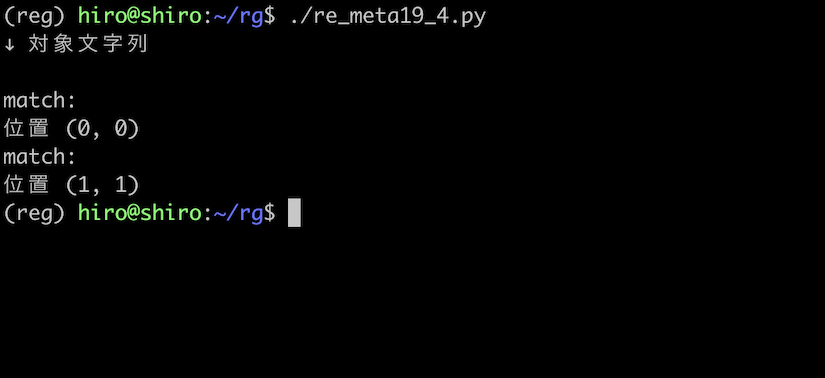
問題無く処理されていますが、半角スペースだと少々見づらいかと思われるので、/ で試してみましょう。
re_meta19_5.py
import re
pattern = re.compile(r"\B")
st = "/a/"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
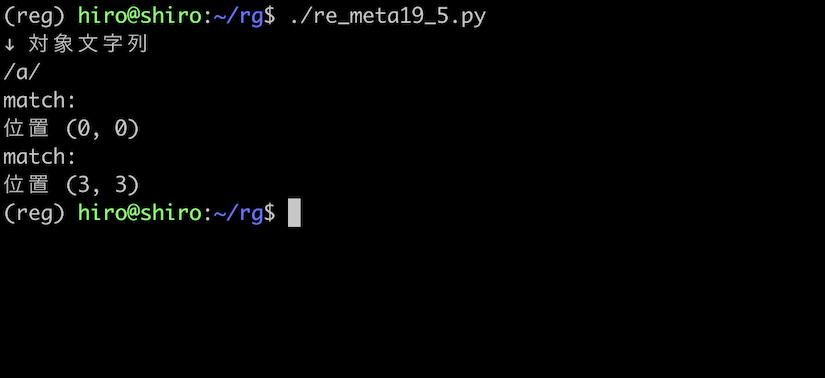
確認し易くなりました。
メタキャラクタと組み合わせて、最初の / のみ取得します。
re_meta19_6.py
import re
pattern = re.compile(r"\B\W")
# 一つ目の \W を取得する
st = "/a/"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
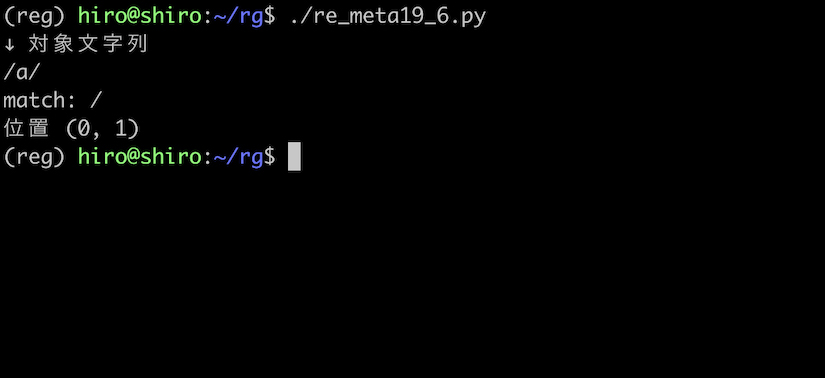
狙い通り、最初の / のみ一致させました。
\W と\W の間
今度は、非単語構成文字と非単語構成文字の境目を取り扱います。
非単語構成文字である / を二つ並べてその間にマッチさせてみましょう。
re_meta19_7.py
import re
pattern = re.compile(r"\B")
# \W と \W の間
st = "a//b"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
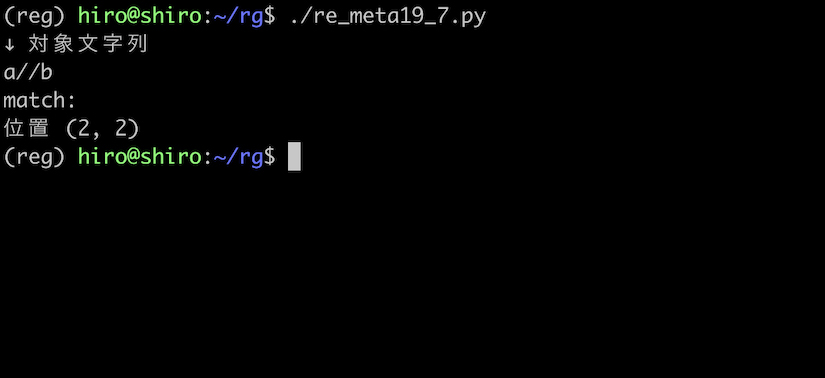
/ と / の間のみ該当しました。
加えて、最初にある / を抽出してみます。
re_meta19_8.py
import re
pattern = re.compile(r"/\B")
# 一つ目の \ を取得する
st = "a//b"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
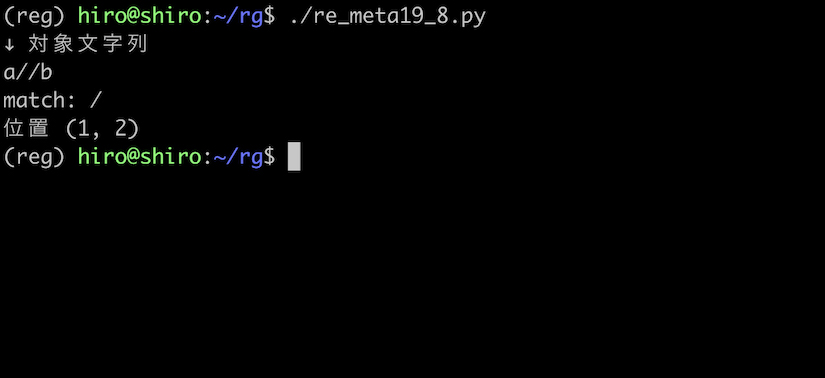
これは特に問題なさそうです。
先頭と\Wの間、\W と末尾の間、\W と\Wの間
非単語構成文字の並びの間に加えて、先頭や末尾と非単語構成文字との間にもマッチする場合を考えます。
例として、タグ(<>)に囲まれている文字列を扱います。
re_meta19_9.py
import re
pattern = re.compile(r"\B")
# 先頭と \W の間、\W と末尾の間、\W と \W の間
st = "<!a>"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
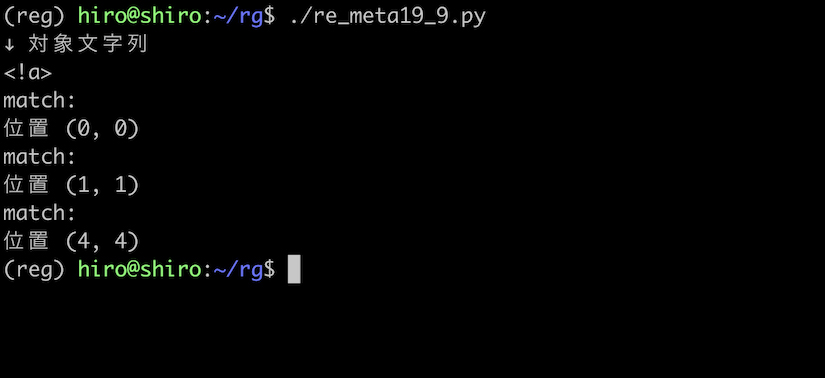
両端にある <> と 先頭や末尾及び、< と ! との間にマッチしました。
それから < の隣にある ! を抽出してみます。
html のコメントで用いられる書式で、 <!---hello!---> のような文字列で試してみましょう。
re_meta19_10.py
import re
pattern = re.compile(r"\B!\B")
# 最初にある ! を取得する
st = "<!---hello!--->"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
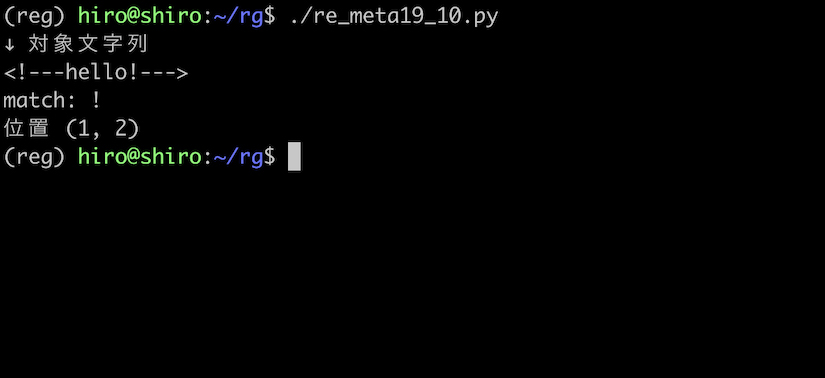
二つある ! のうち < の隣の ! のみを取得出来ました。
ASCIIフラグ
さて、今まではフラグを使ってこなかったので漢字も \w として扱われました。
フラグを使う事により漢字も \W で処理されます。
(フラグ については【\w 単語構成文字】で詳しく説明しています。)
re_meta19_11.py
import re
pattern = re.compile(r"\B",flags=re.ASCII)
st = "一二三"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
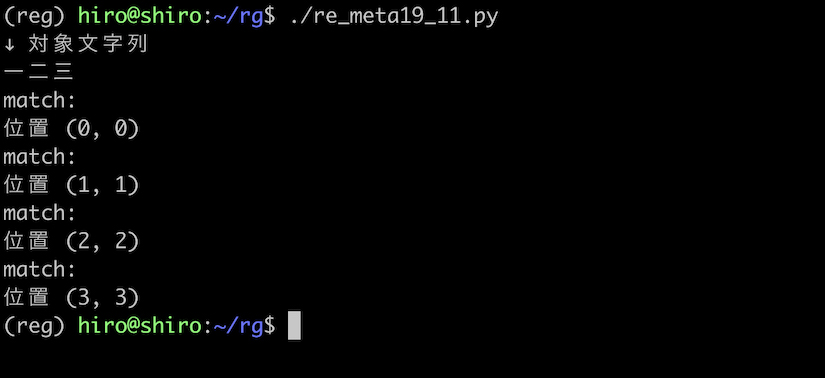
ASCIIフラグにより、一二三 が \W となっています。
漢字が用いられていた meta19_3.py も同様にASCIIフラグを付けてみます。
re_meta19_12.py
import re
pattern = re.compile(r"\B\d\B",flags=re.ASCII)
st = "1月 第2回 A3 4"
print("↓ 対象文字列\n"+st)
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
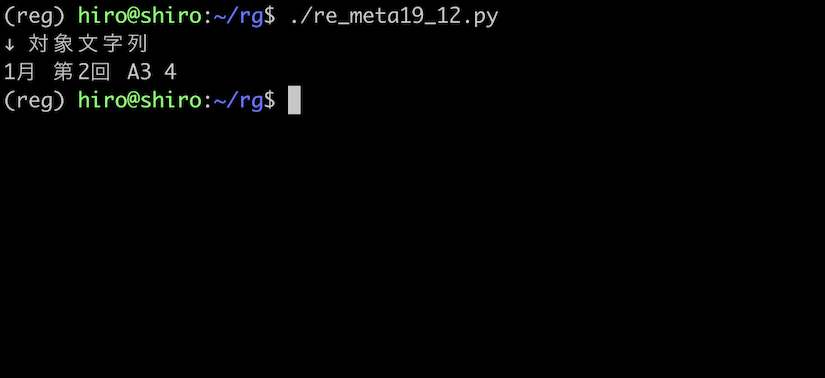
meta19_3.py のときとは異なり、2 はヒットしていません。
空白を調整する
\B と置換処理 を組み合わせて、単語間の空白を調整してみましょう。
(置換 については【正規表現による置換と分割】で詳しく説明しています。)
調整方法は、先頭と末尾の空白は全て除去し、単語間の空白は一つのみとします。
(なお、+ というメタキャラクタを用いていますが、これは繰り返しを意味します。詳しくは 【基礎5 量指定子】 の項目で扱います。)
re_meta19_13.py
import re
pattern = re.compile(r"(^\B +)|(\B +)|( +\B$)")
st = " map max man "
repl = ""
print("↓ 対象文字列\n"+st)
result = pattern.sub(repl,st)
print(result)
実行結果
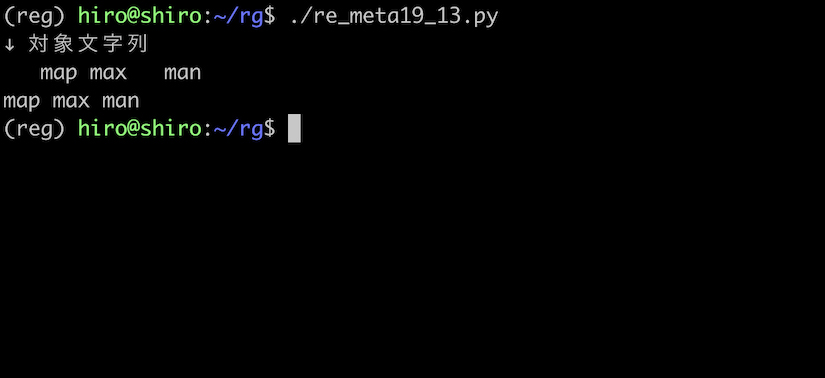
意図した通りに調整できました。
\B の解説は以上です。
ここでも多くの例をみたので、漠然としがちな \B の性質を捉えて、単語の境界でない位置を的確に認識できるようになりました。
前回の \b と合わせて、単語の取り扱いには習熟しています。
関連記事

\b 単語の境界
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラス等。 |
| 学習効果: | 単語の境界とされる位置を的確に認識できるようになる。 |

\B 単語の境界でない
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラス等。 |
| 学習効果: | 単語の境界でない位置を的確に認識できるようになる。 |

(?= ) 先読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 先読みの性質である、任意に設定したパターンの前にマッチする、という事を理解出来る。 |

(?<= ) 後読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 後読みの性質である、任意に設定したパターンの後にマッチする、という事を理解出来る。 |

(?! ) 否定先読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 否定先読みの性質である、任意に設定したパターン以外の前でマッチする、という事を理解出来る。 |

(?<! ) 否定後読み
| 正規表現: | アサーション② |
| 難度 : | 基礎 |
| 事前知識: | Python基礎(reモジュール)。文字クラスや選択等。 |
| 学習効果: | 否定後読みの性質である、任意に設定したパターン以外の後でマッチする、という事を理解出来る。 |

正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |