正規表現基礎
re.A re.I re.M re.S re.X フラグ
カテゴリー:フラグその他

フラグを付けて狙い撃ち!
ここからは、正規表現で用いられるフラグについての説明になります。
フラグを設定する事で、マッチの結果を調整する事が出来ます。
例えば、文字クラスである \d を説明した際に登場した ASCII フラグ というフラグがあります。
このフラグを付けると、対象文字列に対して ASCII限定マッチ を実行出来るようになります。
(\d については【\d 数字を指定する】で詳しく説明しています。)
フラグの付け方ですが、re.compile("パターン(\d など)",re.ASCII 又は flags=re.ASCII) のように記述します。
(なお、Pythonでの記法になります。)
それゆえ、\d の ASCII 限定マッチ なら re.compile("\d",flags=re.ASCII) になります。
インラインフラグ
この他に、インラインフラグを用いる方法もあります
これは文字列パターンの先頭に (?a) を記述して、re.compile("(?a)\d") とする方法です。
主要なフラグ
ここで、この他の主要なフラグを以下に挙げます。
| フラグ | インラインフラグ | 説明 |
|---|---|---|
| re.ASCII re.A | (?a) | \w 、\W 、\b 、\B 、\d 、\D 、\s 、\S を ASCII 限定マッチ にする。 |
| re.IGNORECASE re.I | (?i) | パターンについて大文字・小文字を区別しないマッチングを行う。 |
| re.MULTILINE re.M | (?m) | ^ や $ が、文字列の先頭・末尾だけでなく、各行の先頭 (各改行の直後)・各行の末尾 (各改行の直前)でもマッチする。 |
| re.DOTALL re.S | (?s) | メタキャラクタの . を改行を含めてマッチさせる。 |
| re.VERBOSE re.X | (?x) | パターン中でコメントを記述する。 |
部分適用
さて、インラインフラグについてですが、これはパターンの一部分にのみ適用させる事も可能です。
ASCII 限定マッチの例なら (?a: )を用いて、re.compile("パターン1(?a:パターン2)") とする事で、パターン2 のみASCII 限定マッチにさせる事が出来ます。
また、i や m あるいは s 、x の後に - を付けると対応するフラグを除去します。
記述例としては、re.compile("(?i)パターン1(?-i:パターン2)") などです。
これにより、パターン2 には (?i) が除去されてマッチします。
複数のフラグ
この他にも、複数のフラグを使う場合は次のようにします。
re.compile("パターン",flags = 1つ目のフラグ | 2つ目のフラグ) あるいは、("パターン",1つ目のフラグ | 2つ目のフラグ)
例として re.MULTILINE と re.IGNORECASE を組み合わせるならば、re.compile("^m",flags = re.MULTILINE | re.IGNORECASE) になります。
(^ については【^ 行の先頭】で詳しく説明しています。)
それでは、以下で練習していきます。
この記事の難度は、基礎 Cクラスです。
(A: やさしい → E: 難しい)
事前知識として、pythonから正規表現を扱う方法が必要になります。
また、正規表現における文字クラスの知識や、先頭の位置を表す正規表現である ^ 及び、繰り返しについての量指定子を理解している事が望ましいです。
(不安な人でも、【Pythonから使う】【基礎1 文字クラス】 【^ 行の先頭】【基礎5 量指定子】、で詳しい解説があるので安心です。)
フラグの動作を一つずつ確認しましょう。
| 難度 : | |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。正規表現の文字クラスや繰り返し、行頭等。 |
| 学習効果: | フラグを設定する事で、マッチの結果を調整する事を理解出来ます。 |
Contens | 目次
| Chapter1 | Pythonで実行 |
Chapter1 Pythonで実行
re.ASCII
re.ASCII フラグから検証しましょう。
まず、フラグが何も付いていない状態で実行します。
マッチ対象の文字列が そら@sora空 で、パターンの構成が \w+@\w+ なら漢字などにもマッチするはずです。
(なお、\w については【\w 単語構成文字】、+ については【+ 繰り返し】で詳しく説明しています。)
re_meta30_1.py
import re
pattern = re.compile("\w+@\w+")
st = "そら@sora空"
result = pattern.search(st)
print(result)
実行結果
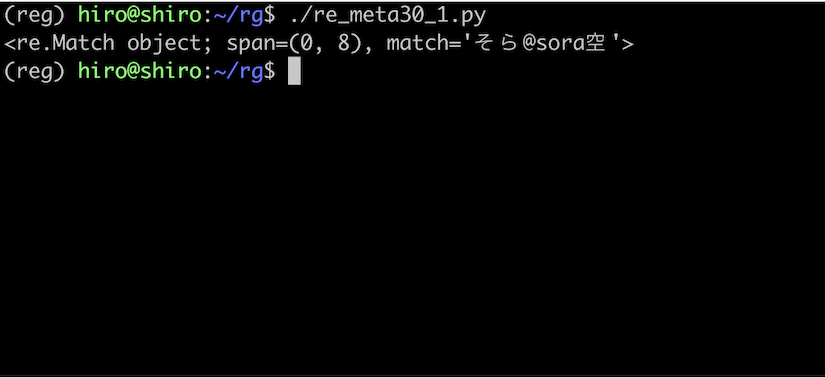
想定通り、そら や 空 にもマッチしました。
では、re.ASCII を付けて再度実行してみましょう。
re_meta30_2.py
import re
pattern = re.compile("\w+@\w+",flags=re.ASCII)
st = "そら@sora空"
result = pattern.search(st)
print(result)
実行結果
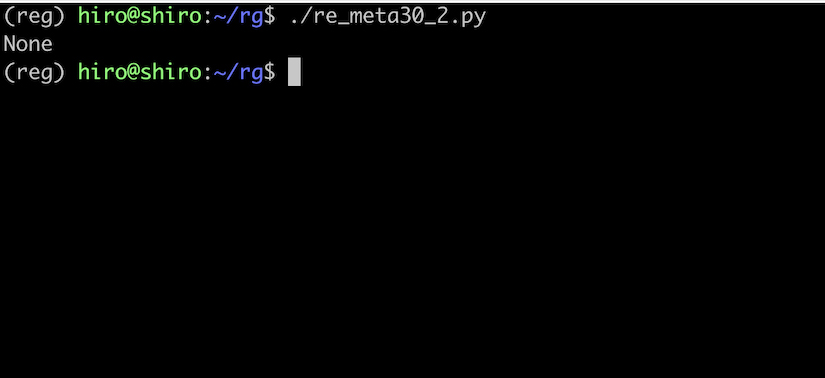
ASCII 限定マッチになったのでヒットしませんでした。
(?a)
今度は、インラインフラグを試してみます。
re_meta30_3.py
import re
pattern = re.compile("(?a)\w+@\w+")
st = "そら@sora空"
result = pattern.search(st)
print(result)
実行結果
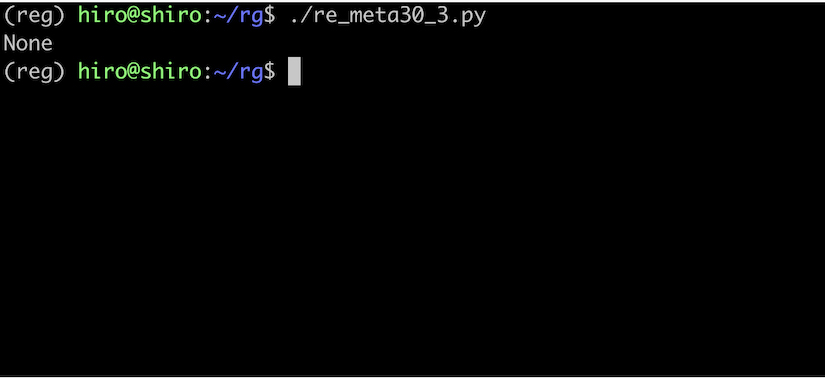
インラインフラグの場合でも meta30_2.py と同様の結果を得られました。
(?a:)
次は、パターンの一部分にのみ適用させます。
文字列パターンを \w+@(?a:\w+) と構成する事で、@ 以降のみ ASCII限定マッチ を行います。
re_meta30_4.py
import re
pattern = re.compile("\w+@(?a:\w+)")
st = "そら@sora空"
result = pattern.search(st)
print(result)
実行結果
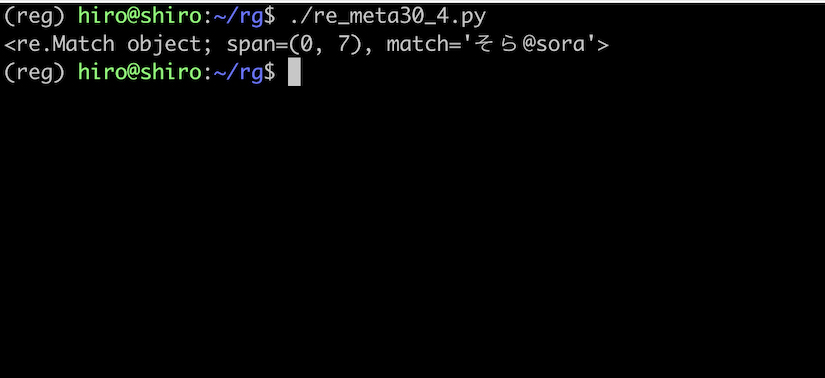
@ の前までは全角文字にもマッチしていますが、@ 以降は ASCII限定マッチ になったので 空 にはマッチしていません。
re.IGNORECASE
パターンについて、大文字・小文字を区別しないマッチングを行わせるフラグである re.IGNORECASE を実行してみましょう。
最初はフラグ無しで実行して、その後フラグを付けて違いを確かめます。
文字列パターンが [a-z]+ の場合、対象文字列に大文字が含まれていると、その箇所はマッチしないはすです。
([a-z] については【[ ] 文字集合を指定する】、+ については【+ 繰り返し】で詳しく説明しています。)
re_meta30_5.py
import re
pattern = re.compile("[a-z]+")
st = "Japan"
result = pattern.search(st)
print(result)
実行結果
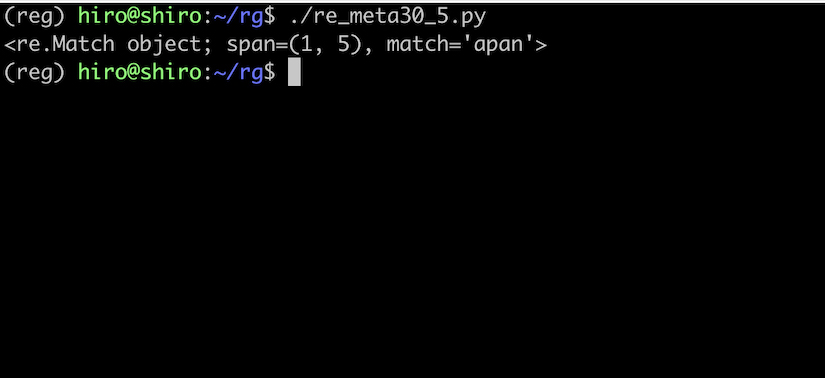
フラグが無いので、大文字の J にはマッチしていません。
それでは re.IGNORECASE を付けてみます。
re_meta30_6.py
import re
pattern = re.compile("[a-z]+",flags=re.IGNORECASE)
st = "Japan"
result = pattern.search(st)
print(result)
実行結果
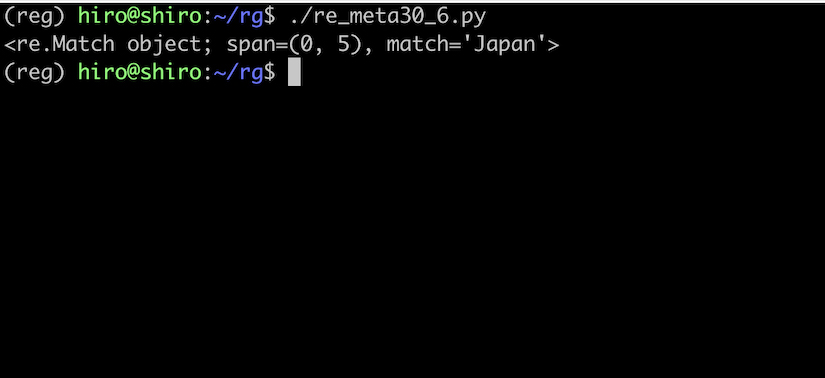
フラグを付けたので大文字の J にもマッチしました。
(?-i:)
続いて re.IGNORECASE をパターンの一部分にのみ適用させる事を試したいと思います。
パターンに部分適用させるには (?-i:) を用いますが、その前に (?i) のみで実行します。
対象文字列を Linear@differentialEquation にして、文字列パターンが (?i)[a-z]+@[a-z]+ なら、Linear の L や Equation の E にもヒットするはずです。
re_meta30_7.py
import re
pattern = re.compile("(?i)[a-z]+@[a-z]+")
st = "Linear@differentialEquation"
result = pattern.search(st)
print(result)
実行結果
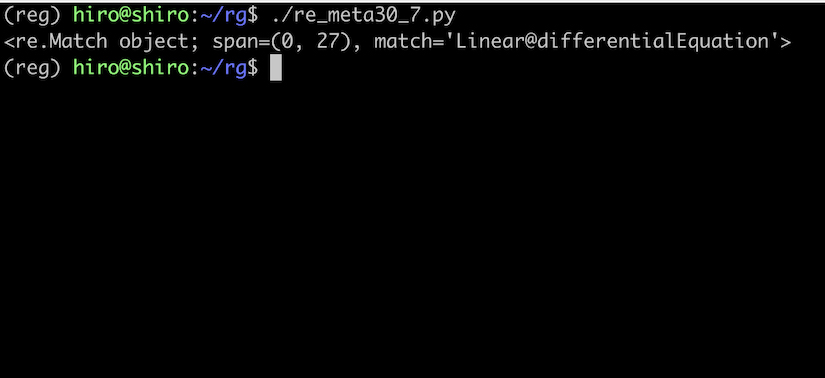
(?i) の効果により、Linear の L や Equation の E にもヒットしました。
では (?-i:) を付けて、@ 以降はフラグの設定を解除するので、パーターンを (?i)[a-z]+@(?-i:[a-z])+ とします。
これにより、Linear の L は一致するが Equation の E については不一致になります。
re_meta30_8.py
import re
pattern = re.compile("(?i)[a-z]+@(?-i:[a-z])+")
st = "Linear@differentialEquation"
result = pattern.search(st)
print(result)
実行結果
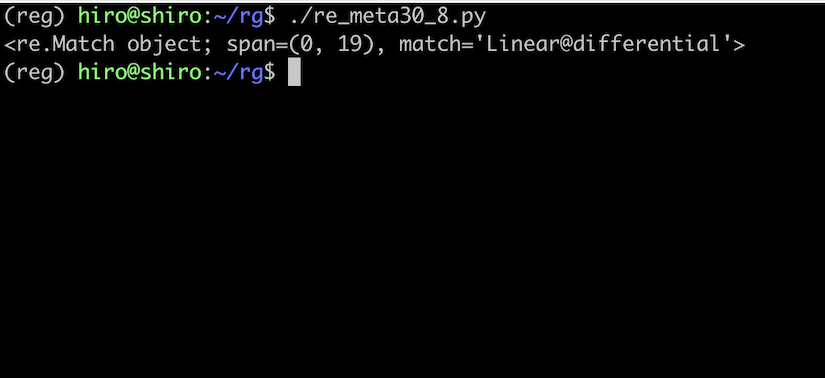
@ 以降はフラグの設定が解除された事が確認出来ました。
re.MULTILINE
re.MULTILINE は、 ^ や $ を、文字列の先頭・末尾だけでなく、各行の先頭 (各改行の直後)・各行の末尾 (各改行の直前)にもマッチさせます。
これもフラグの有無の効果を確かめる為に、最初はフラグ無しで行います。
対象とする文字列は、mathe\nmatics です。
これにつきパターンを ^m にします。
フラグが無い場合、改行直後の m にはマッチしない事を確かめます。
re_meta30_9.py
import re
pattern = re.compile("^m")
st = "mathe\nmatics"
print("↓ 対象文字列\n"+st+"\n↑ 対象文字列")
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
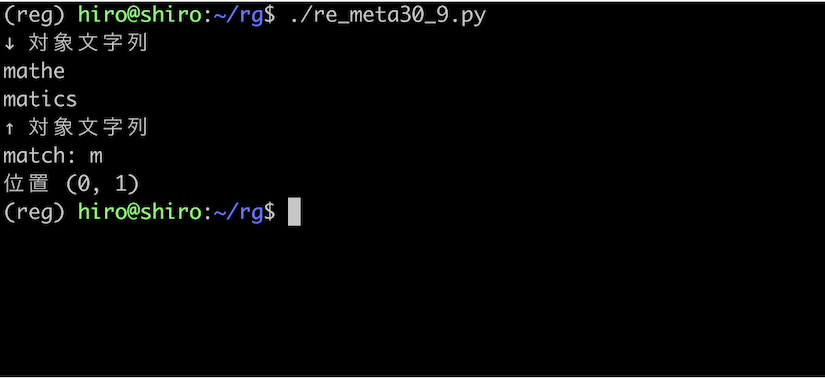
想定通り改行直後の m にはマッチしない事を確認出来ました。
次はフラグを付けてみましょう。
re_meta30_10.py
import re
pattern = re.compile("^m",flags=re.MULTILINE)
st = "mathe\nmatics"
print("↓ 対象文字列\n"+st+"\n↑ 対象文字列")
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
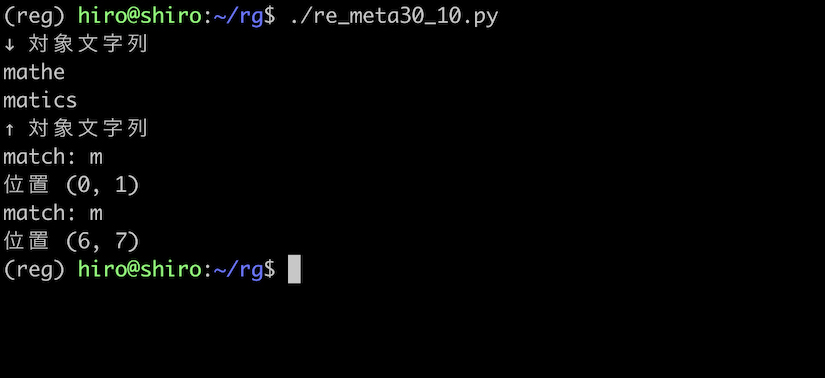
フラグを付けると改行直後の m にもマッチしました。
ところで、対象文字列の mathe\nmatics を mathe\nMatics のように、改行直後の m が大文字の M になった場合、re.MULTILINE だけでは M にマッチしません。
re_meta30_11.py
import re
pattern = re.compile("^m",flags=re.MULTILINE)
st = "mathe\nMatics"
print("↓ 対象文字列\n"+st+"\n↑ 対象文字列")
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
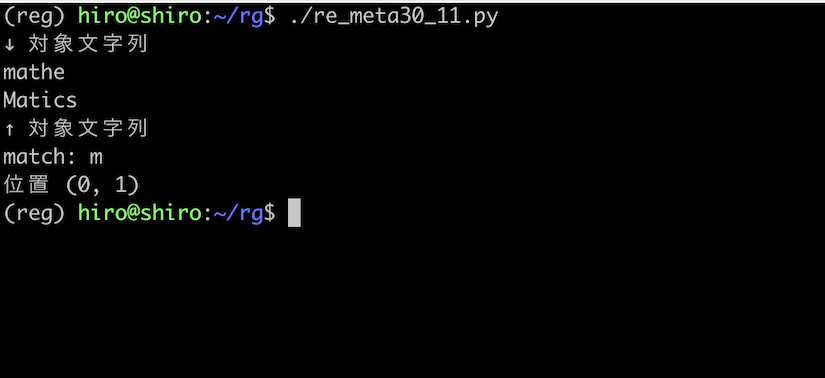
この場合でも改行直後の M にマッチさせるには re.MULTILINE の他に re.IGNORECASE フラグも組み合わせる必要があります。
re.MULTILINE | re.IGNORECASE
複数のフラグを使う場合は、flags = re.MULTILINE | re.IGNORECASE のようにします。
これにより両方のフラグの効果が発生するので、改行直後の M にもマッチするようになります。
re_meta30_12.py
import re
pattern = re.compile("^m",flags=re.MULTILINE | re.IGNORECASE)
st = "mathe\nMatics"
print("↓ 対象文字列\n"+st+"\n↑ 対象文字列")
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
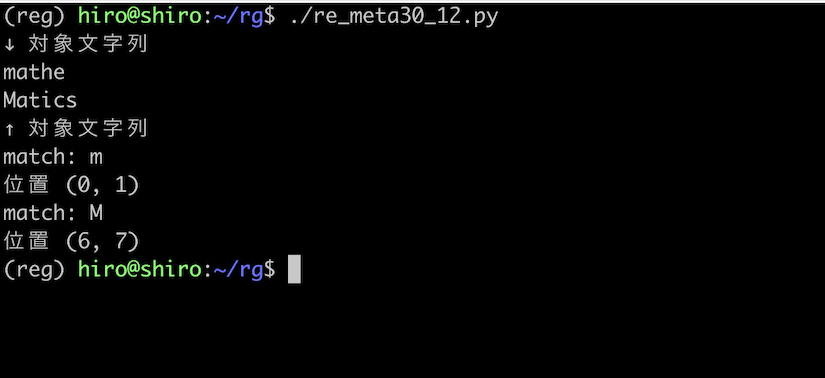
狙い通り改行直後の M にもヒットしました。
re.DOTALL(re.S)
re.DOTALL(又は re.S)は、メタキャラクタの . を改行を含めてマッチさせるフラグです。
(. については【. 改行以外の任意の1文字】で詳しく説明しています。)
例えば、マッチ対象の文字列が <div>\n <h1>title</h1>\n</div> だとします。
フラグが無い場合 . は改行にはマッチしないので、HTMLはバラバラにマッチする事になります。
re_meta30_13.py
import re
pattern = re.compile(".+")
st = "<div>\n <h1>title</h1>\n</div>"
print("↓ 対象文字列\n"+st+"\n↑ 対象文字列")
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
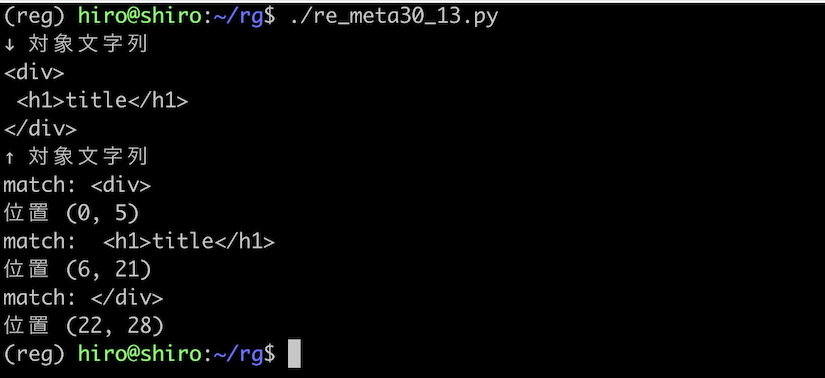
実行結果(続き)
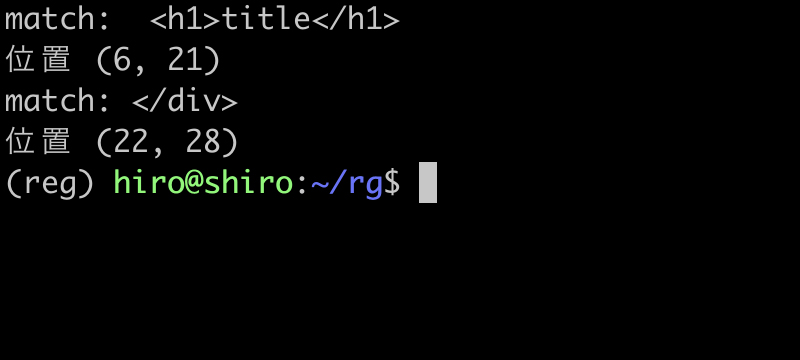
やはりバラバラのマッチになりました。
これに対して re.DOTALL フラグを用いると、HTML が一塊でちょうど良くマッチします。
re_meta30_14.py
import re
pattern = re.compile(".+",flags=re.DOTALL)
st = "<div>\n <h1>title</h1>\n</div>"
print("↓ 対象文字列\n"+st+"\n↑ 対象文字列")
result_iter = pattern.finditer(st)
for result in result_iter:
print("match:",result.group())
print("位置",result.span())
実行結果
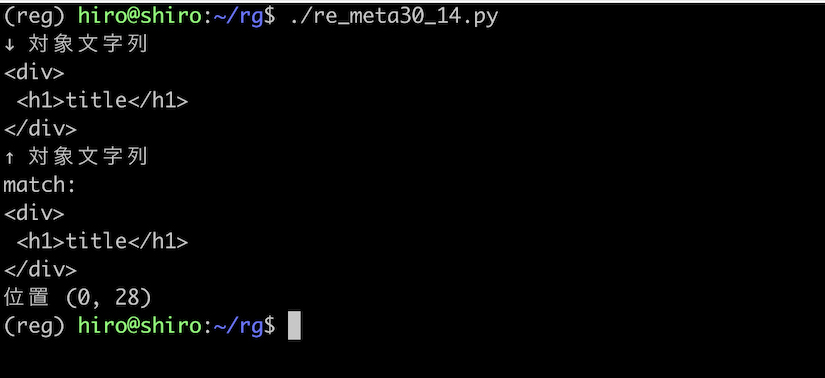
実行結果(続き)
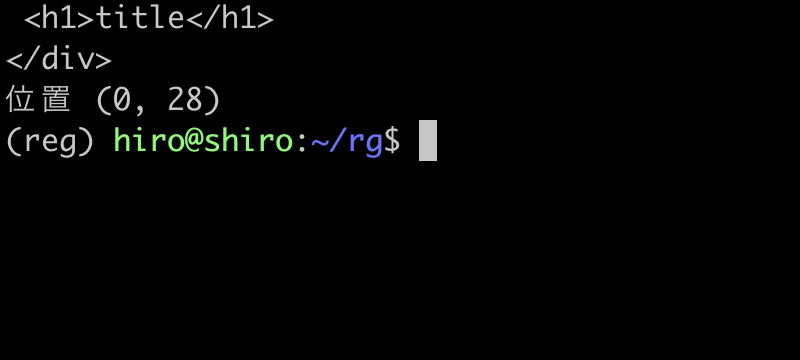
今度は、程よく全体に対してマッチを行えました。
re.VERBOSE
re.VERBOSE を用いると、パターン中でコメントを記述する事が出来るようになります。
文字列パターンの中で # が記述されると、それ以降から行末まではコメントとして扱われます。
例として meta30_8.py の中でコメントを記述してみます。
re_meta30_15.py
import re
pattern = re.compile("""(?i) #IGNORECASEフラグ
[a-z]+ #aからzまでのアルファベット
@(?-i:[a-z])+ #IGNORECASEフラグ解除""",re.VERBOSE)
st = "Linear@differentialEquation"
result = pattern.search(st)
print(result)
実行結果
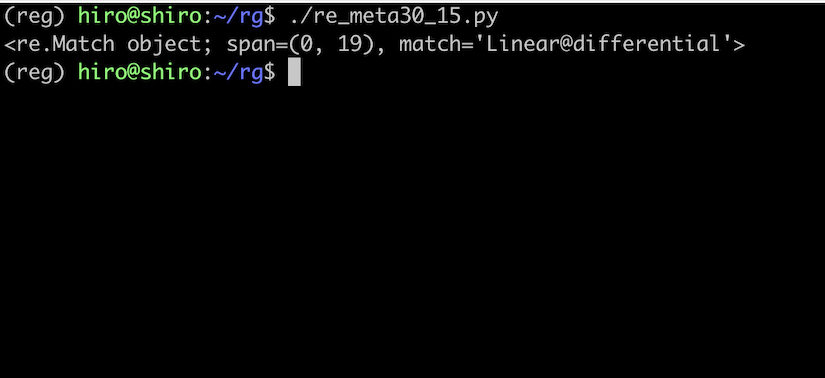
# 以降はコメントとして扱われたので、meta30_8.py と同様な結果を得られました。
但し、注意点としては # の前に \ を付けると結果は異なります。
re_meta30_16.py
import re
pattern = re.compile("""(?i) \#IGNORECASEフラグ
[a-z]+ #aからzまでのアルファベット
@(?-i:[a-z])+ #IGNORECASEフラグ解除""",re.VERBOSE)
st = "Linear@differentialEquation"
result = pattern.search(st)
print(result)
実行結果
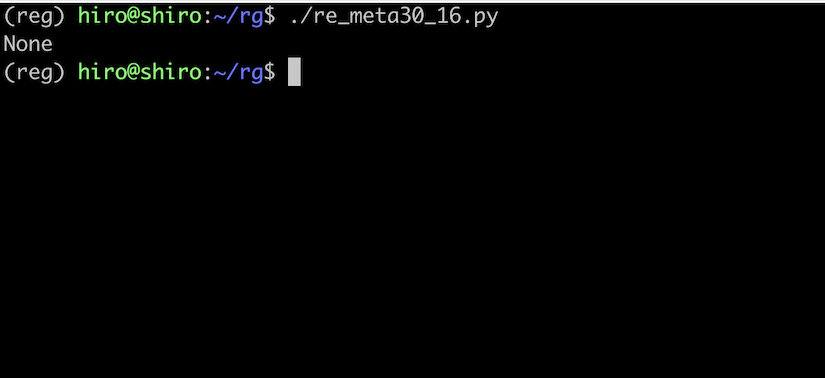
meta30_15.py とは異なる結果になってしまいました。
フラグの解説はここまでにします。
具体的な例をみた事により、フラグがマッチの結果を調整する事を理解出来ました。
これにより、きめ細かなマッチを実現する手段を得られました。
関連記事

re.A re.I re.M re.S re.X フラグ
| 正規表現: | フラグその他 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスや繰り返し、行頭等。 |
| 学習効果: | フラグを設定する事で、マッチの結果を調整する事を理解出来ます。 |

( )?(?( ) | ) 条件
| 正規表現: | フラグその他 |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎。文字クラスや| (または)等。 |
| 学習効果: | if文のような処理を、正規表現でも行える事を習得出来る。 |

正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |